Deep Reinforcement Learning
Introduction
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
Who am I?

- Prof. Dr. Sebastian Peitz
- Chair of Safe Autonomous Systems
- JvF25, Room E16
- https://sas.cs.tu-dortmund.de/
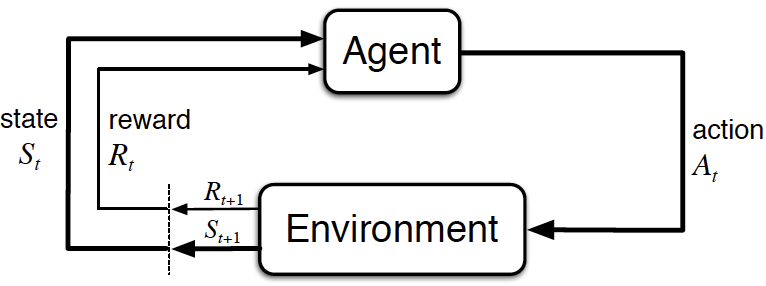
Sequential decision making: Taking actions that affect our environment

Option 1: Rule-based system
- manual design of actions, given some sensor input (such as a camera)
Option 2: Model-based control
- given some model of the dynamics, optimize for the best possible action to take
Option 3: Imitation learning
- collect data from experts and try to clone the behavior
Option 4: Reinforcement learning
- collect data in a trial-and-error fashion, improve via feedback
Reinforcement learning examples (1)
 Grid world
Grid world
- Environment: The grid world
- Agent: The robot
- State \(s\): The robot’s position
- Action \(a\): Move left / right / up / down
- Dynamics \(p(s'|s,a)\): The robot’s new position…
- …deterministically, if the robot does exactly what the action demands
- …stochastically, if there is some noise in the taken action
- Reward: \[r=\begin{cases} +1 & \text{if you reach the target field (top right)} \\ -1 & \text{if you hit the fire} \\ -0.1 & \text{otherwise} \end{cases}\]
- Policy \(\pi\): The strategy according to which you move
Reinforcement learning examples (2)
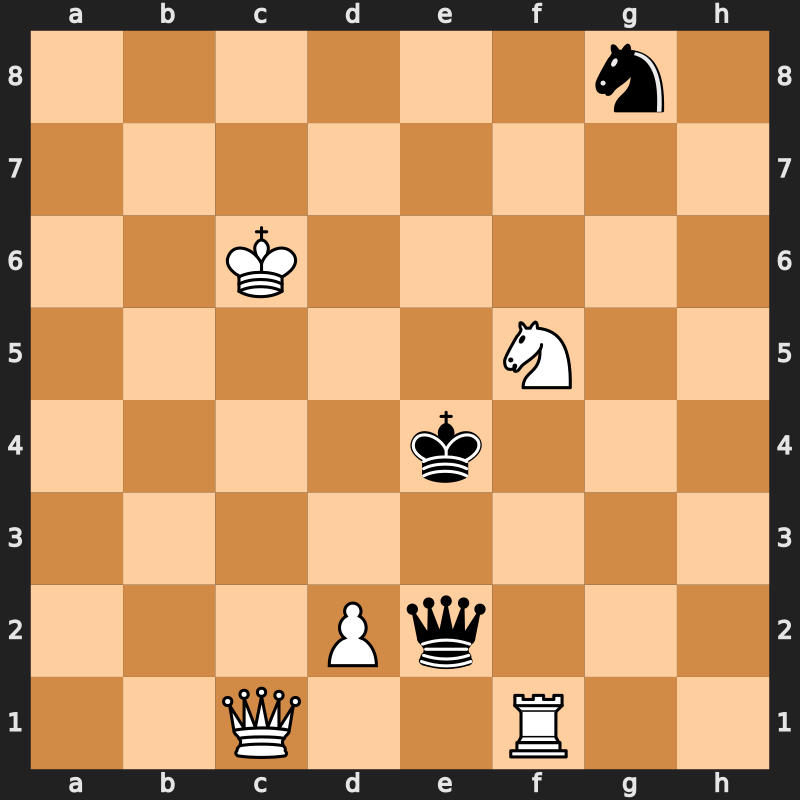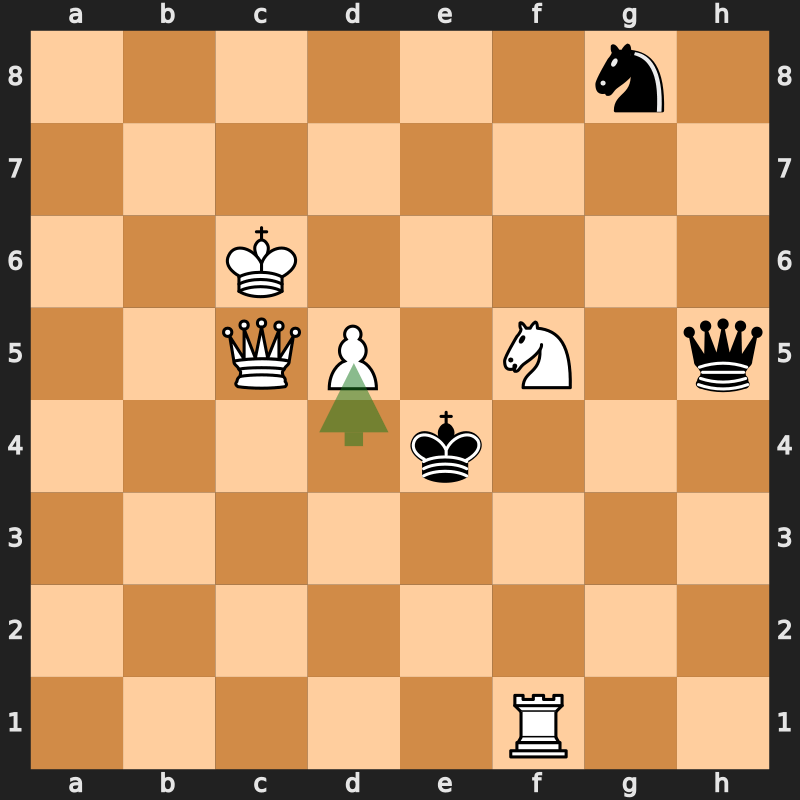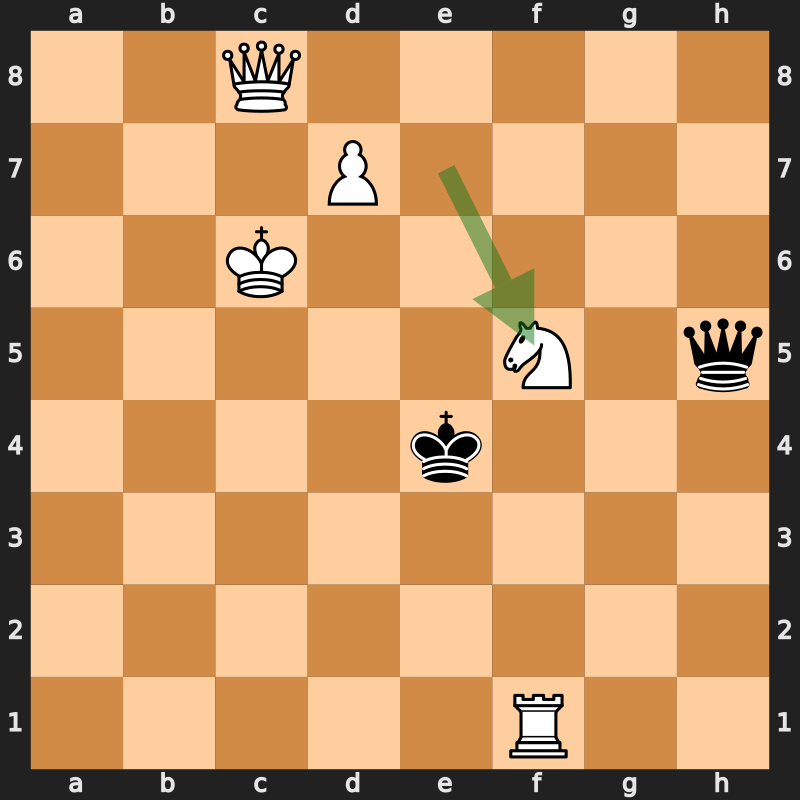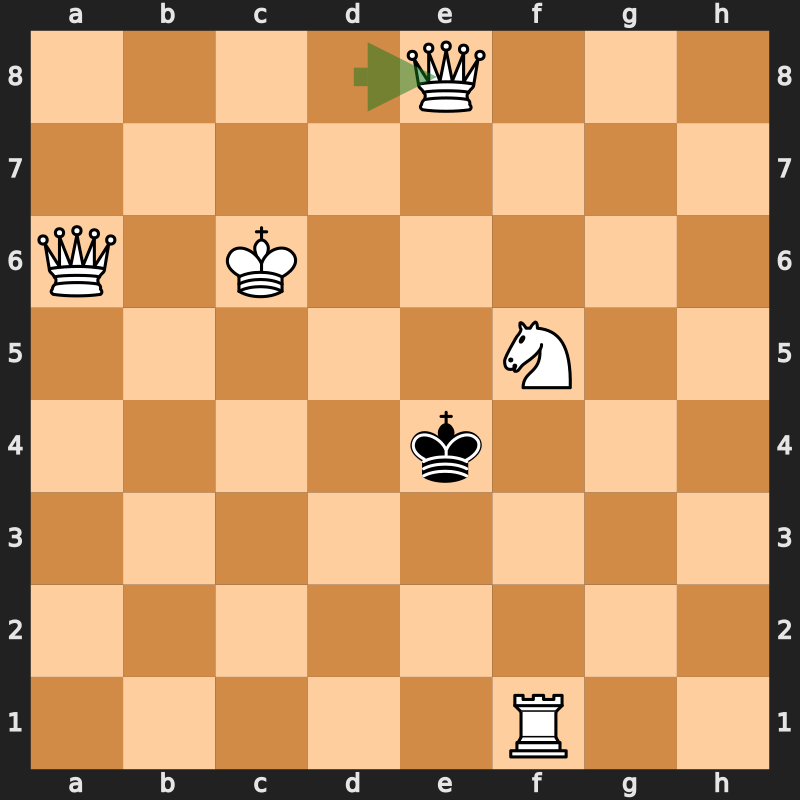 Chess board [Source]
Chess board [Source]
- Environment: The chess board
- Agent: The chess player(s)
- State \(s\): The board position
- Action \(a\): Move one of your figures
- Dynamics \(p(s'|s,a)\): The new board position…
- …after your own and your opponent’s moves \(\rightarrow\) your turn again
- …after your move; it’s the other players turn \(\rightarrow\) two-agent game
- Reward: \[r=\begin{cases} +1 & \text{if you take your opponent's king} \\ -1 & \text{if your king is taken} \\ 0 & \text{otherwise} \end{cases}\]
- Policy \(\pi\): The strategy with which you play

Reinforcement learning examples (3)
 Pendulum [Source]
Pendulum [Source]
- Environment: A pendulum under gravitational force
- Agent: The control system trying to perform a swing-up
- State \(s\): \(\sin\) and \(\cos\) of the angle \(\varphi\) (top: \(\varphi=0\)) and angular velocity \(\omega = \frac{d\varphi}{dt}\)
- Action \(a\): the applied torque
- Dynamics \(p(s'|s,a)\): a differential equation describing the dynamics (Newtonian mechanics) \(\rightarrow\) deterministic system
- Reward: \(r=-(\varphi^2 + 0.1 \cdot \omega^2 + 0.001 \cdot a^2)\)
- Policy \(\pi\): the torque realizing the swing-up
Reinforcement learning examples (4)
 Humanoid [Source]
Humanoid [Source]
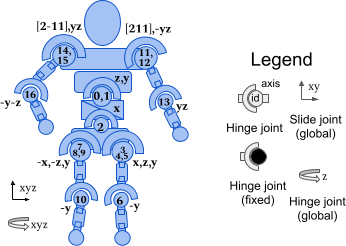
- Environment: A robot moving on a planar ground
- Agent: The control system for actuating the robot
- State \(s\): Positions and velocities of the components (45 in total)
- Action \(a\): The torques applied to the 17 joints
- Dynamics \(p(s'|s,a)\): a differential equation describing the dynamics (Newtonian mechanics) \(\rightarrow\) deterministic system
- Reward: healthy reward + forward reward - control cost - contact cost
- Policy \(\pi\): Run as far as you can!
Reinforcement learning examples (5)
 Atari: Donkey Kong [Source]
Atari: Donkey Kong [Source]

- Environment: Atari video games
- Agent: The “player”
- State \(s\): the pixels of the screen
- Action \(a\): the game pad (i.e., moving, firing, etc.)
- Dynamics \(p(s'|s,a)\): the video game reacting to the player’s actions
- Reward: achieving the game’s goals (stay alive, reach a target, eliminate opponents, …)
- Policy \(\pi\): play such that you achieve your goal as best as possible


{kind=link}
{kind=link}
The key difference to supervised learning
- Supervised learning:
- minimize error on a training dataset \(\Dc=\{(x_1,y_1),\ldots,(x_K,y_k)\}\): \[ \min_\theta \sum_{k=1}^{K} \norm{y_k - f_\theta(x_k)}_2^2 \]
- data is generally drawn independently and identically distributed (i.i.d.): \[ (x_k,y_k)\sim p(\Dc). \]

- Reinforcement learning:
- no supervisor, just a reward signal
- feedback is delayed, not instantaneous
- time really matters (sequential, non i.i.d. data)
- agents actions affect the subsequent data it receives