Deep Reinforcement Learning
Multi-armed bandits
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
Example: Route planning (OH16 to Hansaplatz by car)
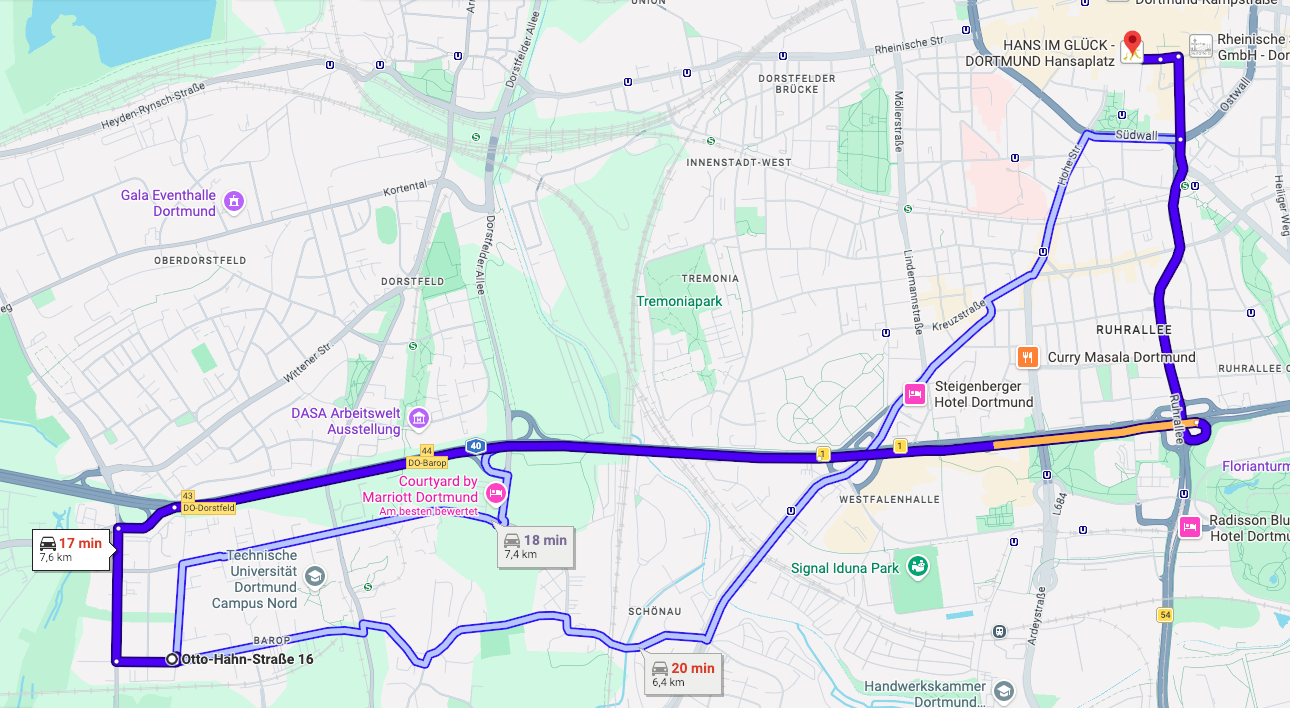
- Let’s assume we do not have access to travel time estimates
- Which route should I take to minimize my travel time?
- Let’s say we can guess the time of one route fairly well
- should we always take this one?
- or try something else and see if we can get better?
- This is known as the exploration-exploitation dilemma
- The route pickig problem is one example of a multi-armed bandit
Multi-armed bandits
- Let us assume that we have a slot machine and we repeatedly can choose between \(k\) different actions
- After each choice \(a_t\) you receive a numerical reward \(r_t\) chosen from a stationary probability distribution\(^*\)
- Objective: maximize the expected total reward over some time period (e.g., over 1000 action selections, or time steps)
- We refer to this as the value: \[ q(a) = \ExpC{r_t}{a_t=a} \]
- If we knew \(q(a)\), then it would be easy to choose!
- Instead, we have to rely on estimates \(Q_t(a)\) which we can iteratively update based on past experience