Deep Reinforcement Learning
Markov Decision Processes
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
Multi-armed bandit notation revisited
- Let us assume that we have a slot machine and we repeatedly can choose between \(k\) different actions.
- After each choice \(A_t\) you receive a numerical reward \(R_t\) chosen from a stationary probability distribution.
- Objective: maximize the value: \[ Q(a) = \ExpC{R_t}{A_t=a}. \]
- We have to rely on estimates \(Q_t(a)\) which we can iteratively update based on past experience.
The RL components in extensive notation
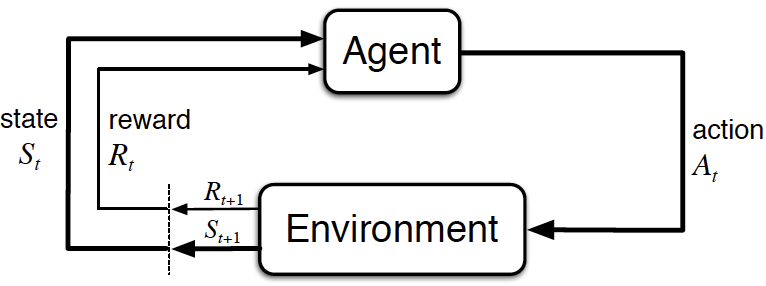
In the literature, we often also find capital letters for state, action and reward to properly account for the probabilistic nature
- \(\pC{S_{t+1}=s'}{S_{t}=s, A_{t}=a}\) is the precise formulation for our short form \(\psprimesa\).
- \(\policy{A_t=a}{S_t=s}\) is the precise formulation for our short form \(\pias\).
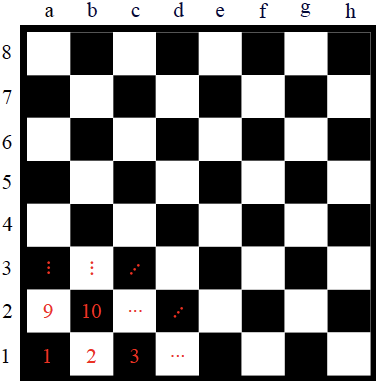
Scalar and vectorial representation in finite MDPs
- The position of a chess piece can be represented in two ways:
- Vectorial: \(s = [s_h, s_v]^\top\), i.e., a two-element vector with horizontal and vertical information,
- Scalar: simple enumeration of all available positions (e.g., \(s = 3\)).
- Both ways represent the same amount of information.
- We will stick to the scalar representation of states and actions in finite MDPs.
Example of a Markov chain (2)

Possible samples for the given Markov chain example starting at \(s=1\) (small tree):
- Small \(\rightarrow\) Gone
- Small \(\rightarrow\) Medium \(\rightarrow\) Gone
- Small \(\rightarrow\) Medium \(\rightarrow\) Large \(\rightarrow\) Gone
- Small \(\rightarrow\) Medium \(\rightarrow\) Large \(\rightarrow\) Large \(\rightarrow\) \(\ldots\)
Example of a finite Markov reward processes

- Growing larger trees is rewarded:
- advantageous for the environment,
- appreciated by hikers,
- useful for wood production.
- Loosing a tree is unrewarded.
Returns for the forest MRP
Exemplary samples for \(g\) with \(\gamma = 0.5\), starting with the planting (\(s=1\)): \[ \begin{align*} s &= 1 \rightarrow 4, & g &= 0, \\ s &= 1 \rightarrow 2 \rightarrow 4, & g &= 1 + 0.5 \cdot 0 = 1, \\ s &= 1 \rightarrow 2 \rightarrow 3 \rightarrow 4, & g &= 1 + 0.5 \cdot 2 + 0.25 \cdot 0 = 2, \\ s &= 1 \rightarrow 2 \rightarrow 3 \rightarrow 3 \rightarrow 4, & g &= 1 + 0.5 \cdot 2 + 0.25 \cdot 3 + 0.125 \cdot 0 = 2.75. \end{align*} \]
The Value function
The state-value function \(V(s)\) (or simply value function) of an MRP is the expected return starting from state \(s\) at time \(t\): \[ V(s) = \ExpC{g_t}{s_t = s}. \]
- Represents the expected long-term value of being in state \(s\).
Example of an MDP: Wood cutting

- Two actions possible in each state:
- Wait \(a = w\): let the tree grow.
- Cut \(a = c\): gather the wood.
- With increasing tree size the wood reward increases.
Policy (1)
In an MDP environment, a policy is a distribution over actions given states: \[ \policy{a_t}{s_t} = \pC{a_t}{s_t}.^* \]
- In MDPs, policies depend only on the current state.
- A policy completely defines the agent’s behavior (which might be stochastic or deterministic).
{kind=link}
Bellman expectation equation & forest tree example (2)

- Discount factor: \(\gamma = 0.8\)
- Disaster probability: \(\alpha = 0.2\)
Bellman expectation equation & forest tree example (3)
Using the Bellman expectation from \(\eqref{eq:MDP_BellmanQ}\), the action values can be calculated directly:

Optimal police for wood cutting MDP: state value (1)
Start with \(V(s=4)\) and continue backwards \[ \begin{align*} V^*(4) &= 0 \\ V^*(3) &= \max \begin{cases} 1 + \gamma \left[ (1-\alpha) V^*(3) + \alpha V^*(4) \right] \\ 3 + \gamma V^*(4) \end{cases} \\ &= \max \begin{cases} 1 + \gamma \left[ (1-\alpha) V^*(3)\right] \\ 3 \end{cases} \\ V^*(2) &= \max \begin{cases} 0 + \gamma \left[ (1-\alpha) V^*(3) + \alpha V^*(4) \right] \\ 2 + \gamma V^*(4) \end{cases} \\ &= \max \begin{cases} \gamma \left[ (1-\alpha) V^*(3) \right] \\ 2 \end{cases} \\ V^*(1) &= \max \begin{cases}\gamma \left[ (1-\alpha) V^*(2) \right] \\ 1 \end{cases} \\ \end{align*} \]
Optimal police for wood cutting MDP: state value (2)
- Possible solutions:
- numerical optimization approach (e.g., simplex method, gradient descent,…)
- manual case-by-case equation solving (dynamic programming, next lecture)

Optimal police for wood cutting MDP: state value (3)
- Possible solutions:
- numerical optimization approach (e.g., simplex method, gradient descent,…)
- manual case-by-case equation solving (dynamic programming, next lecture)
