Deep Reinforcement Learning
Dynamic Programming
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
A DP example from production (1)
- to produce a certain product, four operations (denoted by \(A\), \(B\), \(C\), and \(D\)) must be performed on a certain machine.
- We assume that operation \(B\) can be performed only after operation \(A\) has been performed, and operation \(D\) can be performed only after operation \(C\) has been performed. (Thus the sequence \(CDAB\) is allowable but the sequence \(CDBA\) is not.)
- The setup cost \(C_{mn}\) for passing from any operation \(m\) to any other operation \(n\) is given.
- There is also an initial startup cost \(S_A\) or \(S_C\) for starting with operation \(A\) or \(C\), respectively.
- The cost of a sequence is the sum of the setup costs associated with it; for example, the operation sequence \(ACDB\) has cost \[S_A + C_{AC} +C_{CD}+C_{DB}.\]
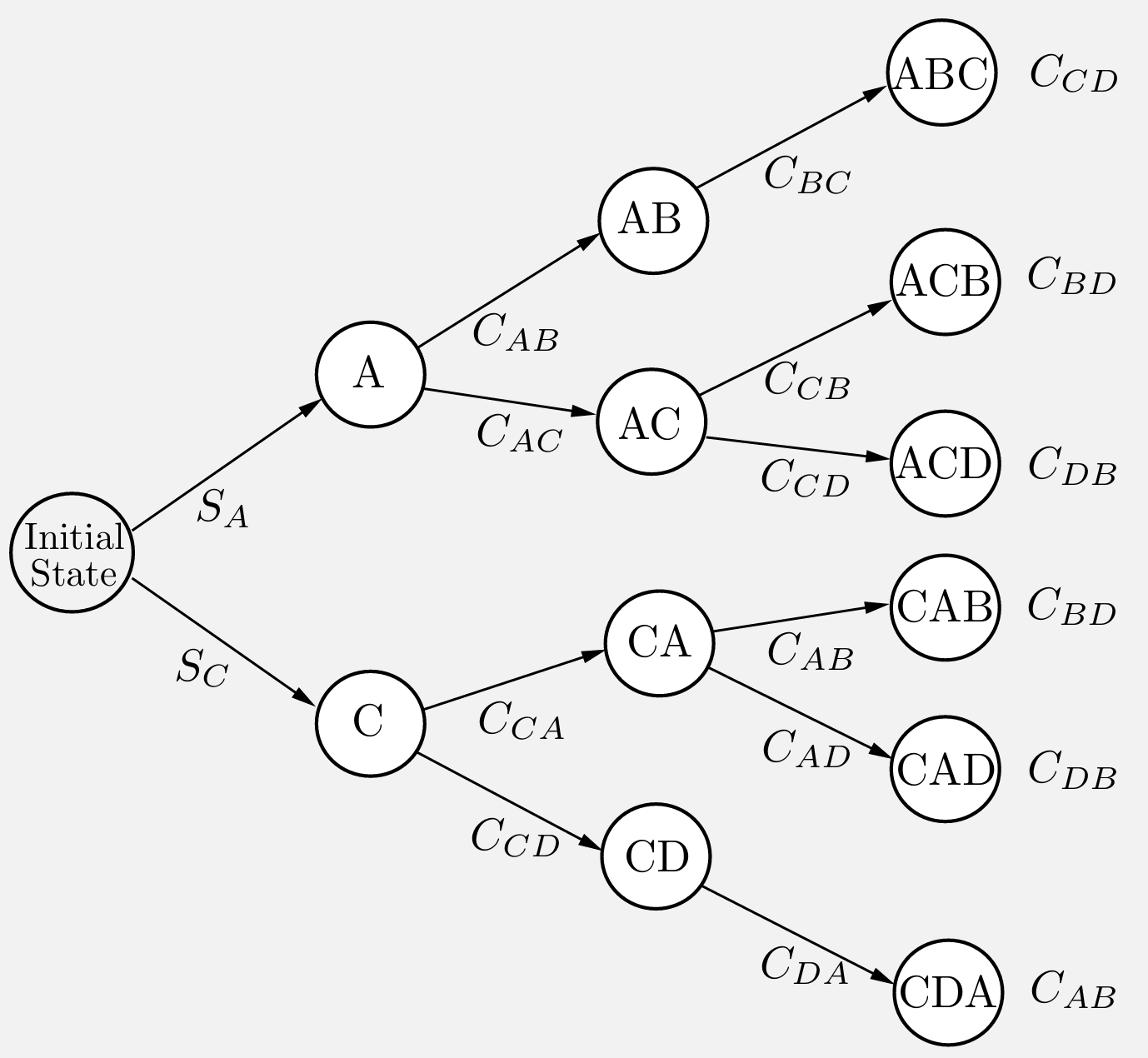
Question: In this example, what is (in the context of RL)
- the state \(s\)?
- the action \(a\) (and action set \(\Ac(s)\))?
The two central tasks in RL
In all chapters, we will distinguish between two core learning tasks in reinforcement learning:
- The prediction problem (evaluation)
- For a fixed policy \(\pi\), we want to estimate the Value function \(V^\pi(s)\) (or the Q function \(Q^\pi(s,a)\))
- The methods vary strongly in terms of the knowledge we have, e.g.,
- We know \(p\): Dynamic programming.
- We don’t know \(p\): Learning from experience (Monte Carlo, temporal difference learning, …).
- Many variations and combinations exist!
- The control problem (improvement)
- We want to improve our policy \(\pi\) towards the optimal \(\pi^*\) that maximizes the value function.
- This usually requires a back-and-forth between 1. and 2. (known as generalized policy iteration (GPI)).
- Given our estimate of \(V^\pi\) / \(Q^\pi\), we improve the policy: \(\pi' > \pi\).
- This invalidates \(V^\pi\) / \(Q^\pi\) \(\Rightarrow\) update estimates: \(V^{\pi^\prime}\) / \(Q^{\pi^\prime}\).
- We then further improve \(\pi''>\pi'\), and so on.

Example: Gridworld
We have a small robot in a gridworld that wants to recharge.
\(\bullet\) Initial state \(s_0\): a random valid field.
\(\bullet\) Goal: reach the battery (\(r=1\), otherwise \(r=0\)).
\(\bullet\) \(\Ac=\set{\uparrow, \downarrow, \leftarrow, \rightarrow}\) (leaving or invalid field \(\Rightarrow\) no movement).
\(\bullet\) \(\policy{\cdot}{s} = [0.25, 0.25, 0.25, 0.25]^\top ~\forall~ s\in\Sc\).
\(\bullet\) Discount factor: \(\gamma = 0.8\).
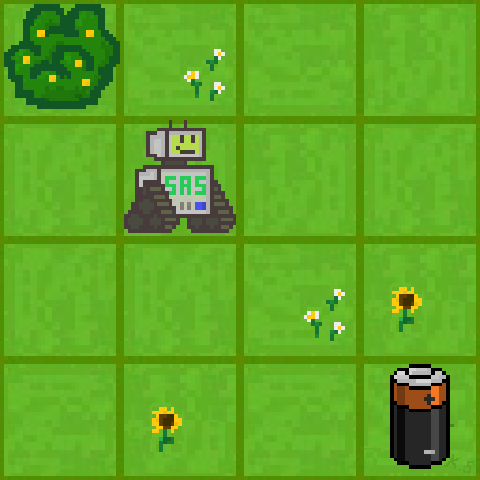
 Random policy
Random policy
\(\bullet\) Terminal state: If the robot hits the battery, it receives \(r=1\) (potentially discounted) and the episode ends.
\(\bullet\) Optimal strategy: Move towards the battery as quickly as possible.
Value iteration (1)
- What’s the main drawback of policy iteration?
\(\Rightarrow\) it’s expensive to solve the policy evaluation loop in each iteration (nested loops!) - Do we have to wait until convergence of \(V_k\) to \(V^\pi\) every time?
\(\Rightarrow\) the gridworld example suggested no!

- Value iteration: truncate the policy evaluation after one step!