Deep Reinforcement Learning
Brief Introduction to Deep Learning
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
Bias-variance tradeoff (1)
\(\bullet\) In the ML context, bias denotes the error of the average model \(\overline{f}_{\theta}\) when repeating the training with different datasets \(\Dc_{\mathsf{train},1},\Dc_{\mathsf{train},2},\ldots\): \[ \mathsf{bias} = \Expsub{\left(\overline{f}_{\theta}(x) - f(x)\right)^2}{x\sim\Dtest}. \]
\(\bullet\) variance denotes the variability in between the individual training runs: \[ \mathsf{variance} = \Expsub{\Expsub{\left(f^{(\Dc)}_{\theta}(x) - \overline{f}_{\theta}(x)\right)^2}{\Dc\sim\{\Dc_{\mathsf{train,\ell}}\}_{\ell=1}^\infty}}{x\sim\Dtest}. \]
\(\Rightarrow\) Often a matter of model complexity.
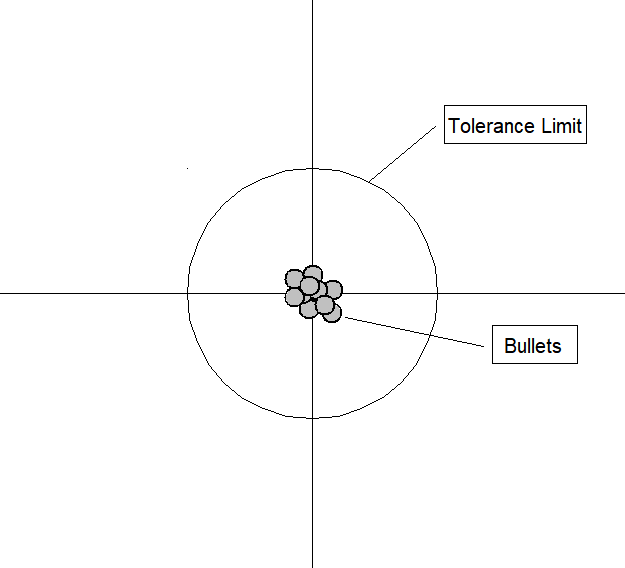 Low bias, low variance
Low bias, low variance
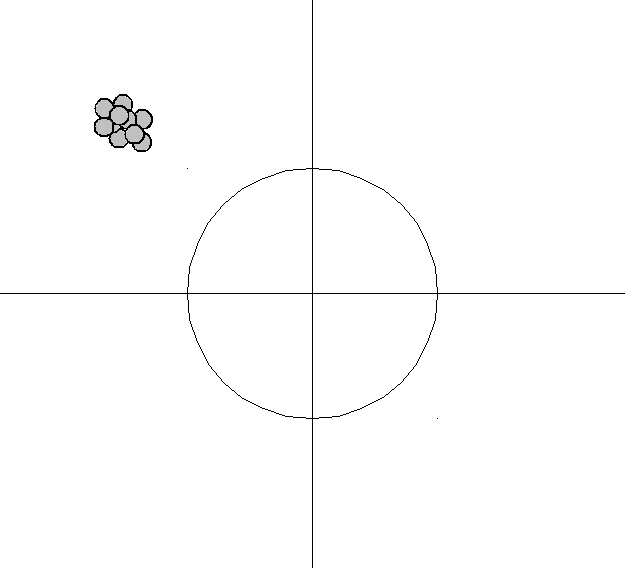 Large bias, low variance
Large bias, low variance
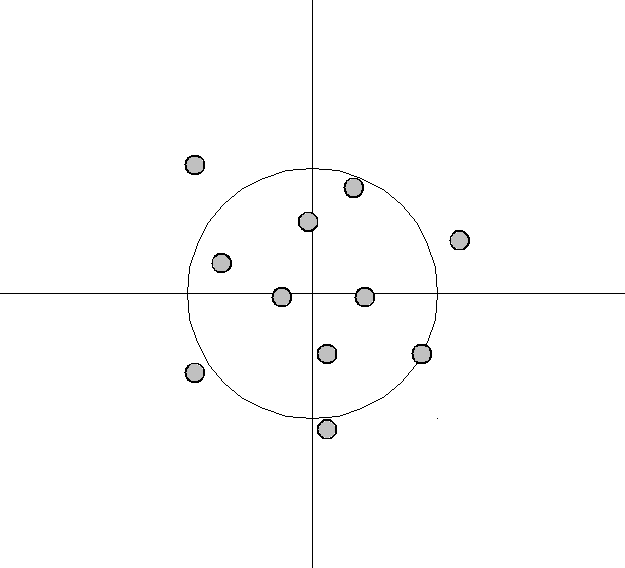 Low bias, large variance
Low bias, large variance
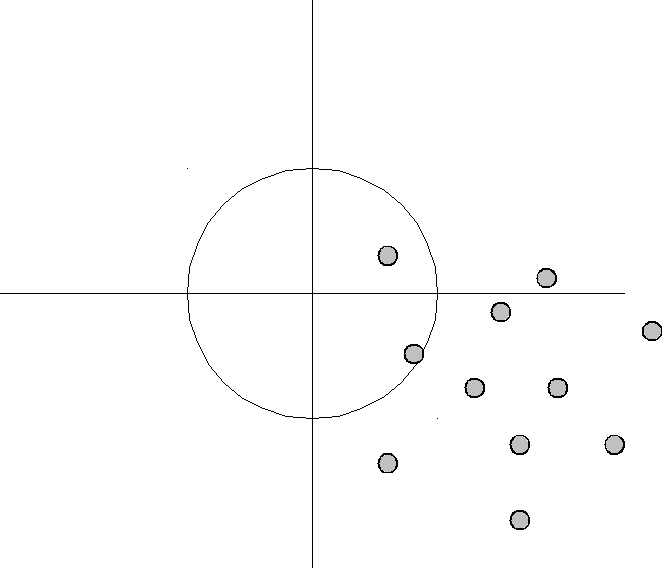 Large bias, large variance [Wikipedia]
Large bias, large variance [Wikipedia]
Bias-variance tradeoff (2)
Example (see Wikipedia): Fitting a model of serveral radial basis functions to noisy trainig data: \[ f_\theta(x) = \sum_{k=1}^d \theta_k \exp\left(-\frac{1}{2}\frac{x-c_k}{\sigma_k^2}\right). \]
\(\bullet\) For a wide spread (i.e., large \(\sigma_k\)), the bias is high: the RBFs cannot fully approximate the function (especially the central dip), but the variance between different trials is low.
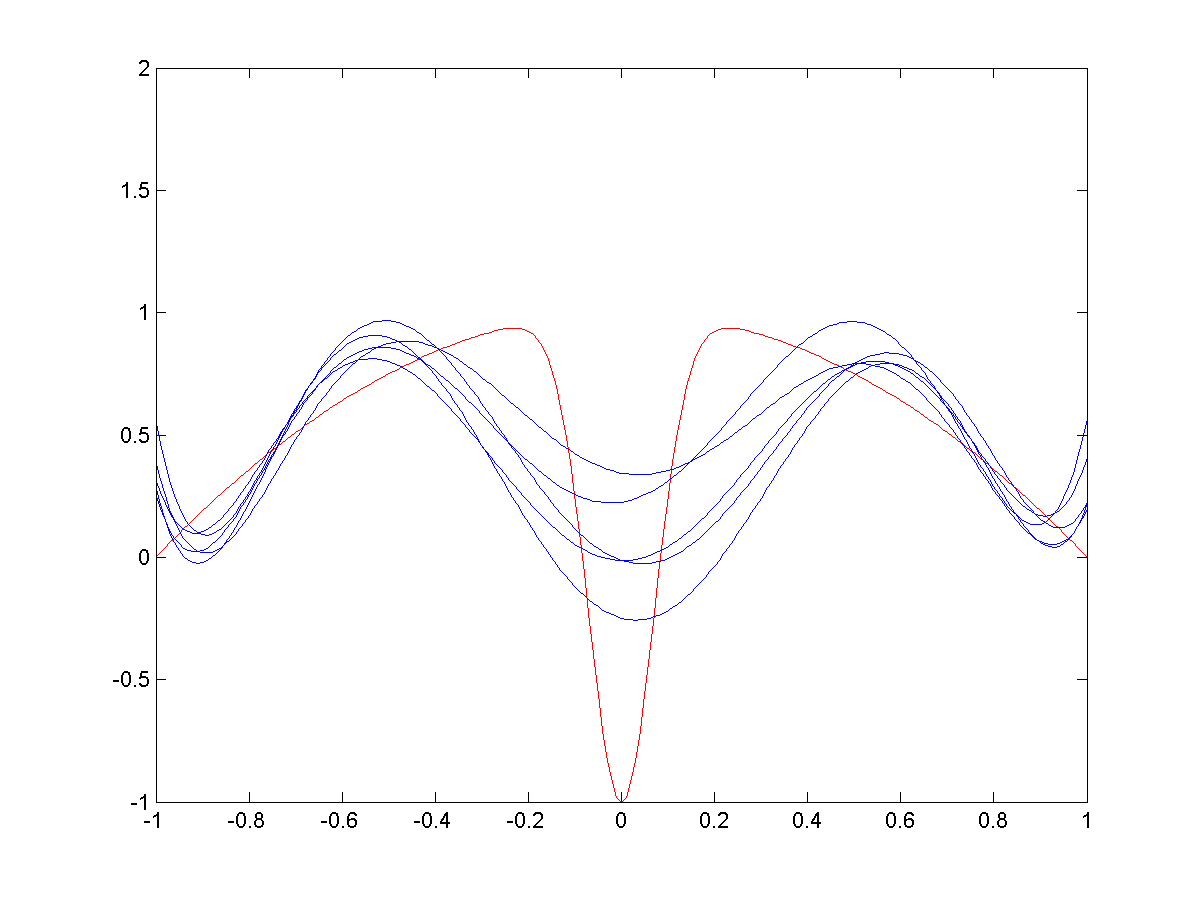
\(\bullet\) As spread decreases (image 3 and 4) the bias decreases: the blue curves more closely approximate the red…
\(\bullet\) … but the variance between trials (\(\Dc_{\mathsf{train,1}},\Dc_{\mathsf{train,2}},\ldots\)) increases.
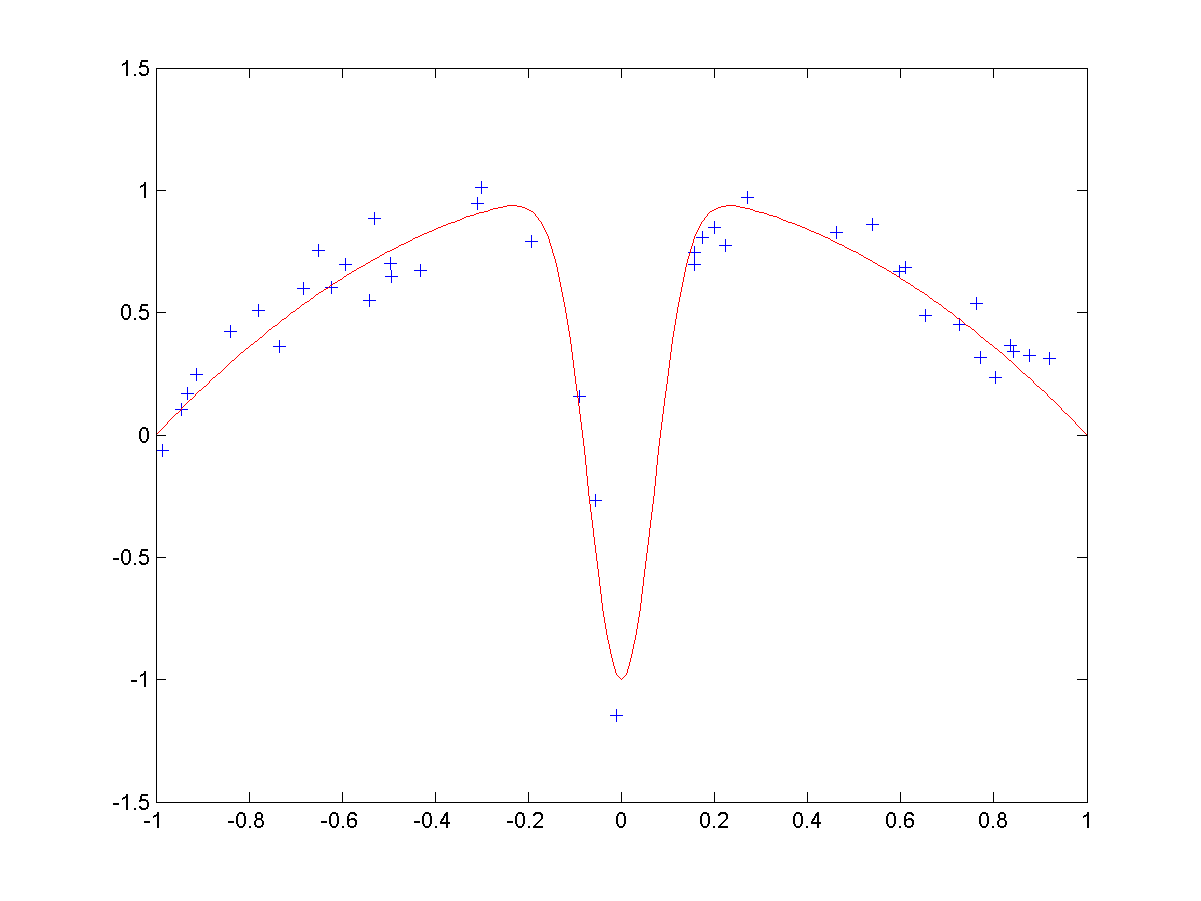
 Wide spread RBFs.
Wide spread RBFs.
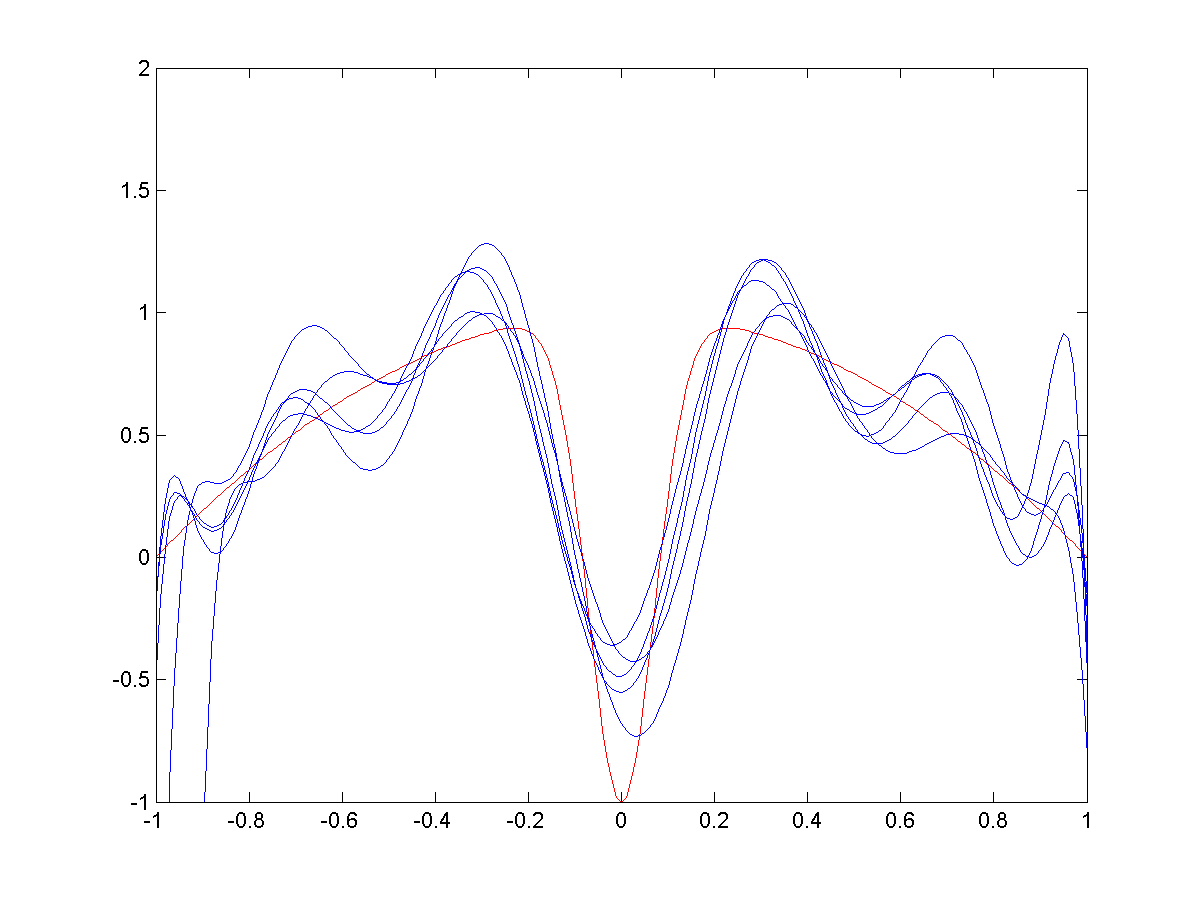 Medium spread RBFs.
Medium spread RBFs.
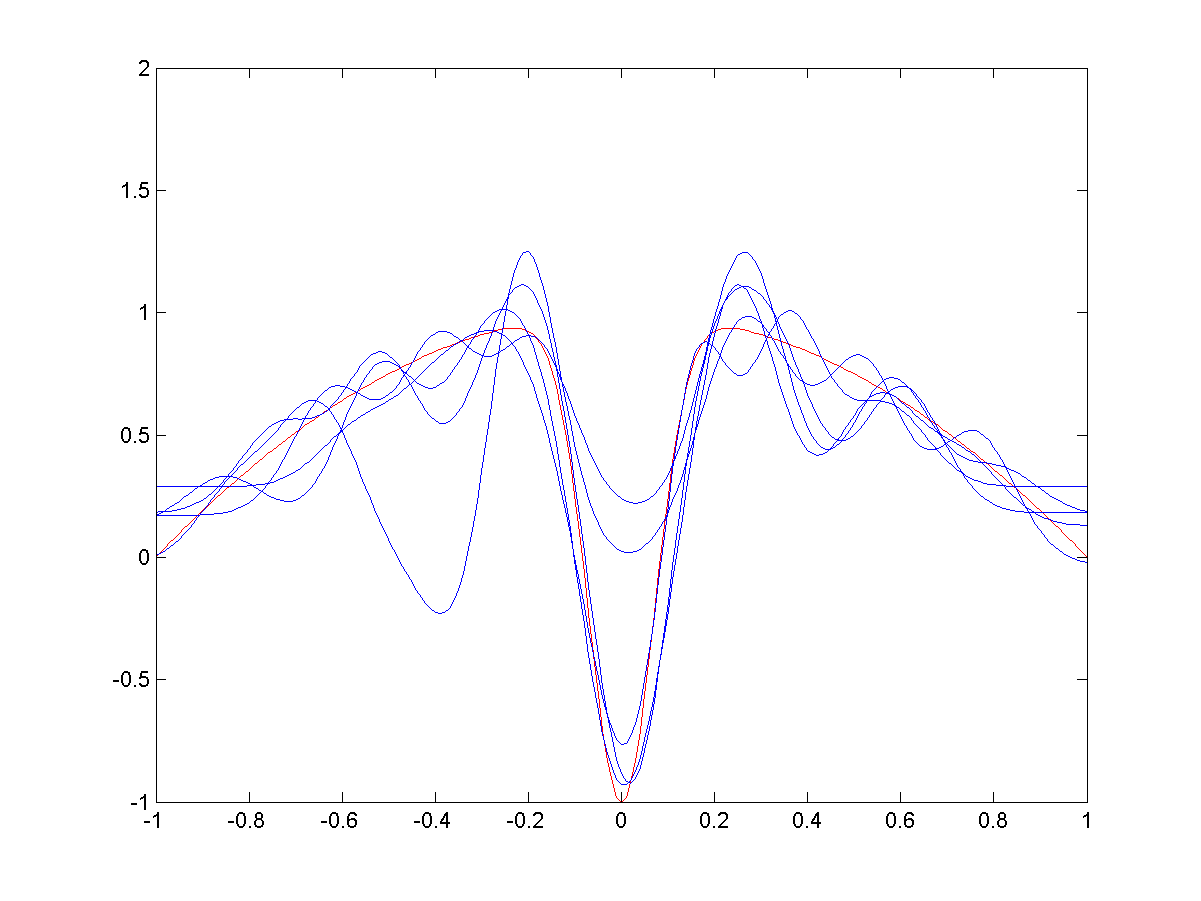 Small spread RBFs.
Small spread RBFs.
Cross-validation
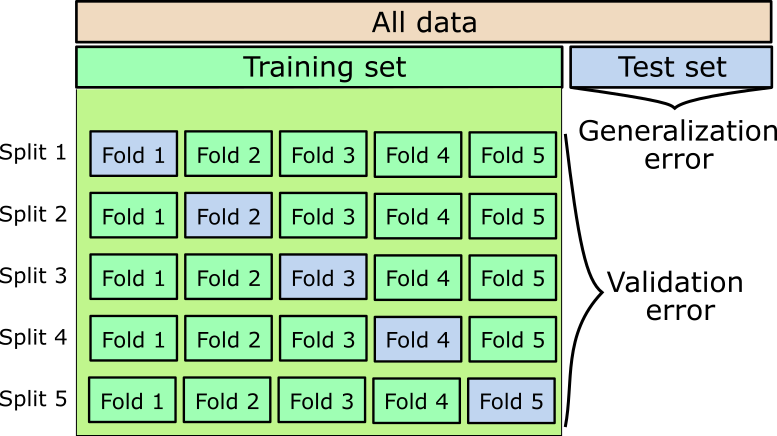
- Training is repeated \(k\) times with \(k\) different splits of the training set.
- Each observation serves as unseen instance (blue boxes) at least once.
- The validation error is an indicator for tuning hyperparameters.
- Example of a \(k\)-fold Cross-validation (CV).
Artificial neural networks
Artificial neural networks (ANNs) are nonlinear function approximators \(\hat{y}=f_\theta(x)\) that
- are end-to-end differentiable.
- are stacks of minimal units, the artificial neurons.

- An ANN consists of nodes or neurons in one or more layers.
- Each node transforms the weighted sum of all previous nodes (plus a potential bias term) through an activation function \(\sigma\): \[ \sigma\left( \theta_0 + \sum_{k=1}^n \theta_k x_k \right). \]
- The weighted connections are called edges, which represent the ANN’s parameters.
Multi-layer perceptron
Standard model of supervised learning: multi-layer perceptron or feed-forward ANN.

- Only forward-flowing edges.
- The depth \(L\) and width \(\iterate{H}{\ell}\) are hyperparameters.
- With \(\iterate{\sigma}{\ell}\) and \(\iterate{z}{\ell}\) denoting the activation function and activation of layer \(\ell\) respectively, we get for the output in the \(\th{\ell}\) layer. \[ \iterate{x}{\ell}= \iterate{\sigma}{\ell}\big( \underbrace{\iterate{\Theta}{\ell}\iterate{x}{\ell-1} + \iterate{b}{\ell}}_{\iterate{z}{\ell}} \big) ,\] with input \(\iterate{x}{0}=x\) and output \(\iterate{x}{L}=y\):
- Training:
- Summarize the full set of parameters (i.e., weight matrices \(\iterate{\Theta}{\ell}\in\R^{\iterate{H}{\ell} \times \iterate{H}{\ell-1}}\) and biases \(\iterate{b}{\ell}\)) under \(\theta\).
- Iteratively update the weights using gradient information.
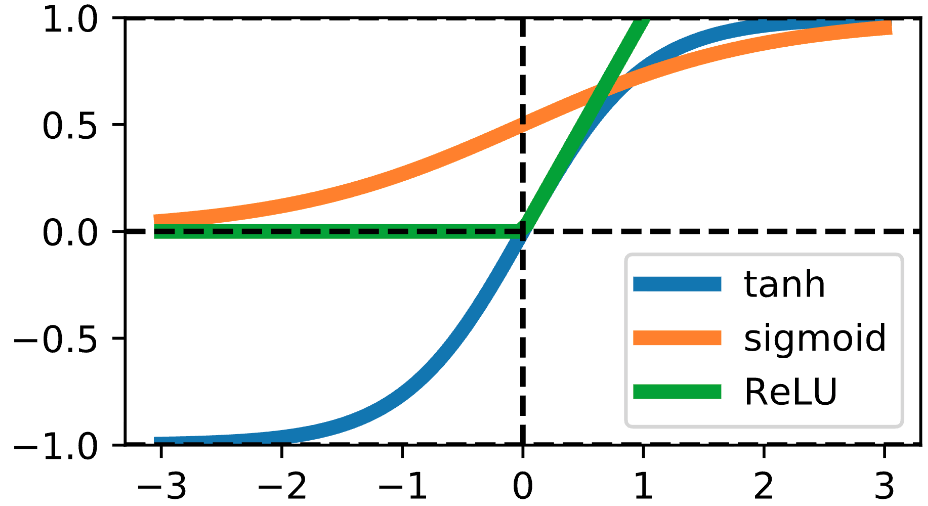
Activation functions
- The source of nonlinearity in neural networks.\(^*\)
- Common choices for \(\sigma(z)\) are
- \(\sigma(z) = \tanh(z)\),
- Sigmoid: \(\sigma(z) = \frac{1}{1+e^{-z}}\),
- Rectified linear unit (ReLU): \(\sigma(z) = \max(0, z)\),
- The activation of the output layer, \(\iterate{\sigma}{L}(z)\), is task-dependent. For instance,
- regression: \(y=\iterate{\sigma}{L}(\iterate{z}{L})=\iterate{z}{L}\), i.e., \(\iterate{\sigma}{L} = \mathsf{Id}\) is the identity mapping.
- binary classification: sigmoid (i.e., probability), followed by a rounding step to either \(0\) or \(1\).
- multi-class classification: \(y_i=\frac{\exp(\iterate{z}{L}_i)}{\sum_j \exp(\iterate{z}{L}_j)}\) (softmax).
Training (1)
- Training is performed in an iterative manner: \[\theta \gets \theta + \eta \delta\theta.\]
- \(\eta\in\R_{>0}\) is the step size or learning rate.
- \(\delta\theta\in\R^d\) is the update direction, usually a gradient-based descent direction.
- Numerous variants for \(\delta\theta\). The strongest contain additional momentum terms such as the Adam algorithm (Kingma and Ba 2014). We remember the previous update \(\delta\theta^{-}\) and thereby flatten out zig-zag behavior.
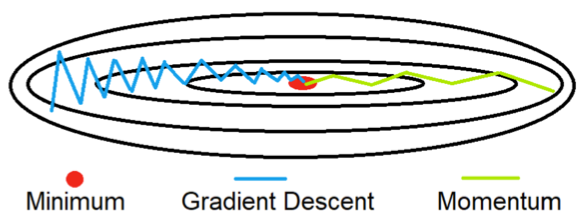 Source
Source
- First, we need to define a loss function that we wish to minimize.
- Regression: (root) mean square error, mean absolute error.
- Classification: cross entropy.
- Additional terms, e.g., regularization, physics information, …
- Iterations over the dataset \(\Dtrain\) are called epochs.
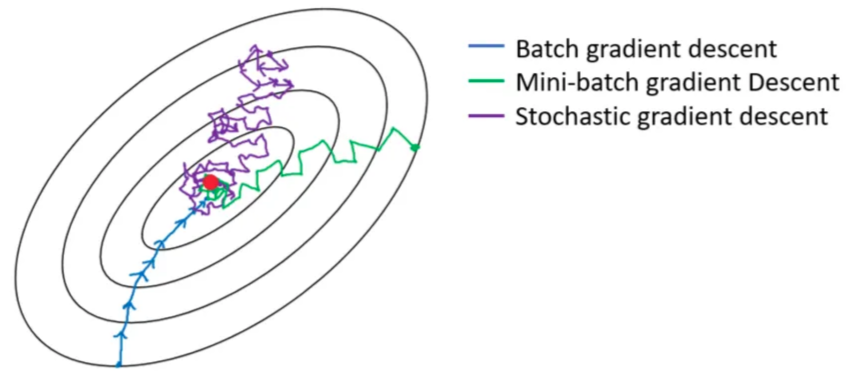
Stochastic gradient descent and batch learning
- The cost for a single gradient step scales with the dataset size \(N\), which can be very large.
- For each sample, we need to perform one forward and one backward pass.
- Stochastic gradient descent (SGD): massive speedup by using a single sample per step insetad of the entire dataset, \[\delta \theta = \nabla L(\theta; x_k), \qquad k\sim U(\{1,\ldots,N\}). \]
- Mini-batch gradient descent with \(s\in\{1,\ldots,N\}\) samples per step: compromise ground between efficiency and noisiness, \[ \delta \theta = \frac{1}{s} \sum_{k\in\mathcal{I}} \nabla L(\theta; x_k), \qquad \text{where}~\mathcal{I}~\text{is an $s$-dimensional, ranodmly drawn subset of $\{1,\ldots,N\}$}.\]
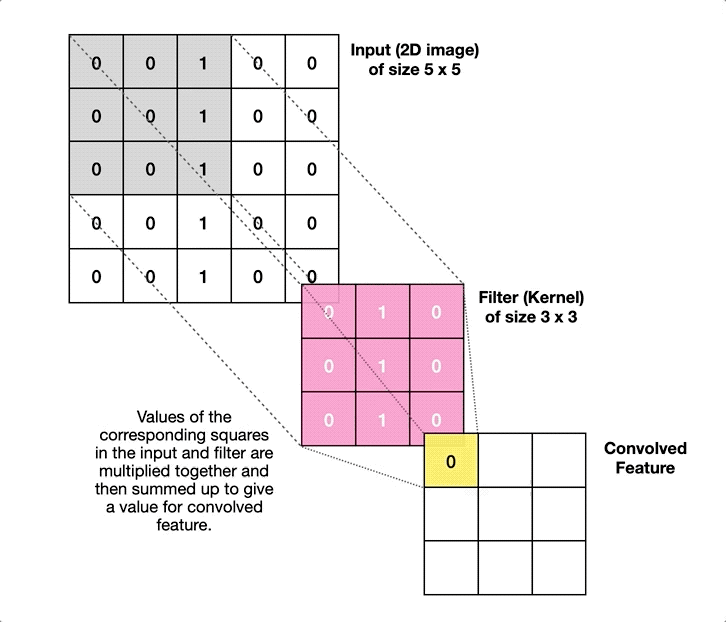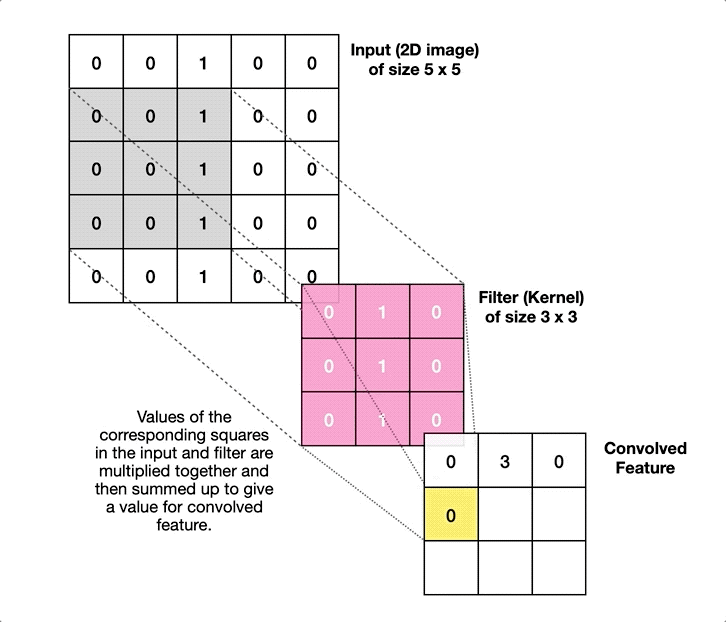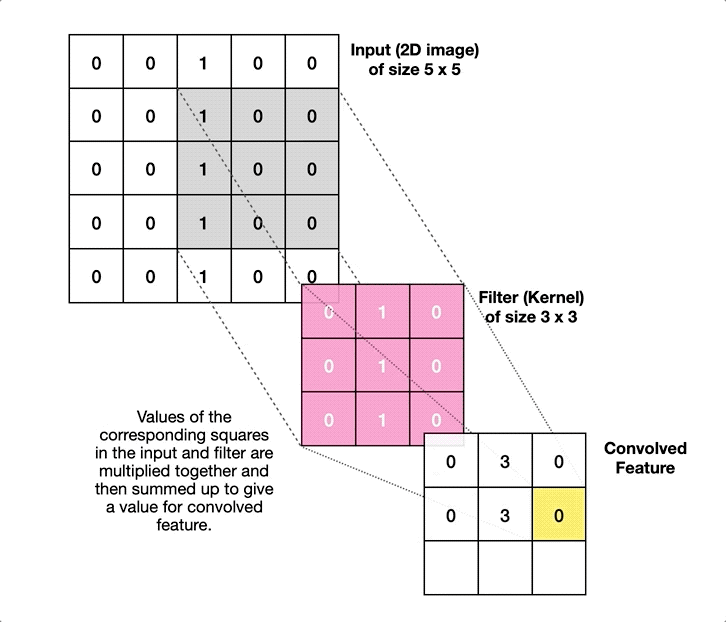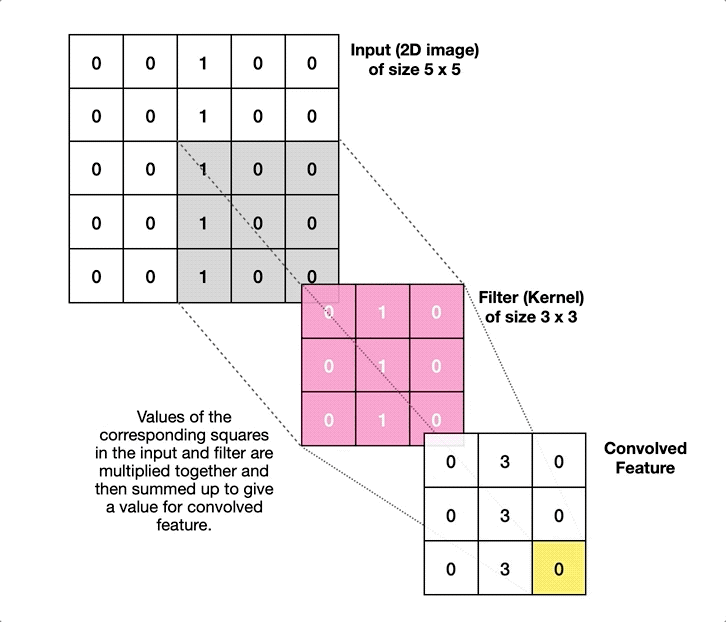
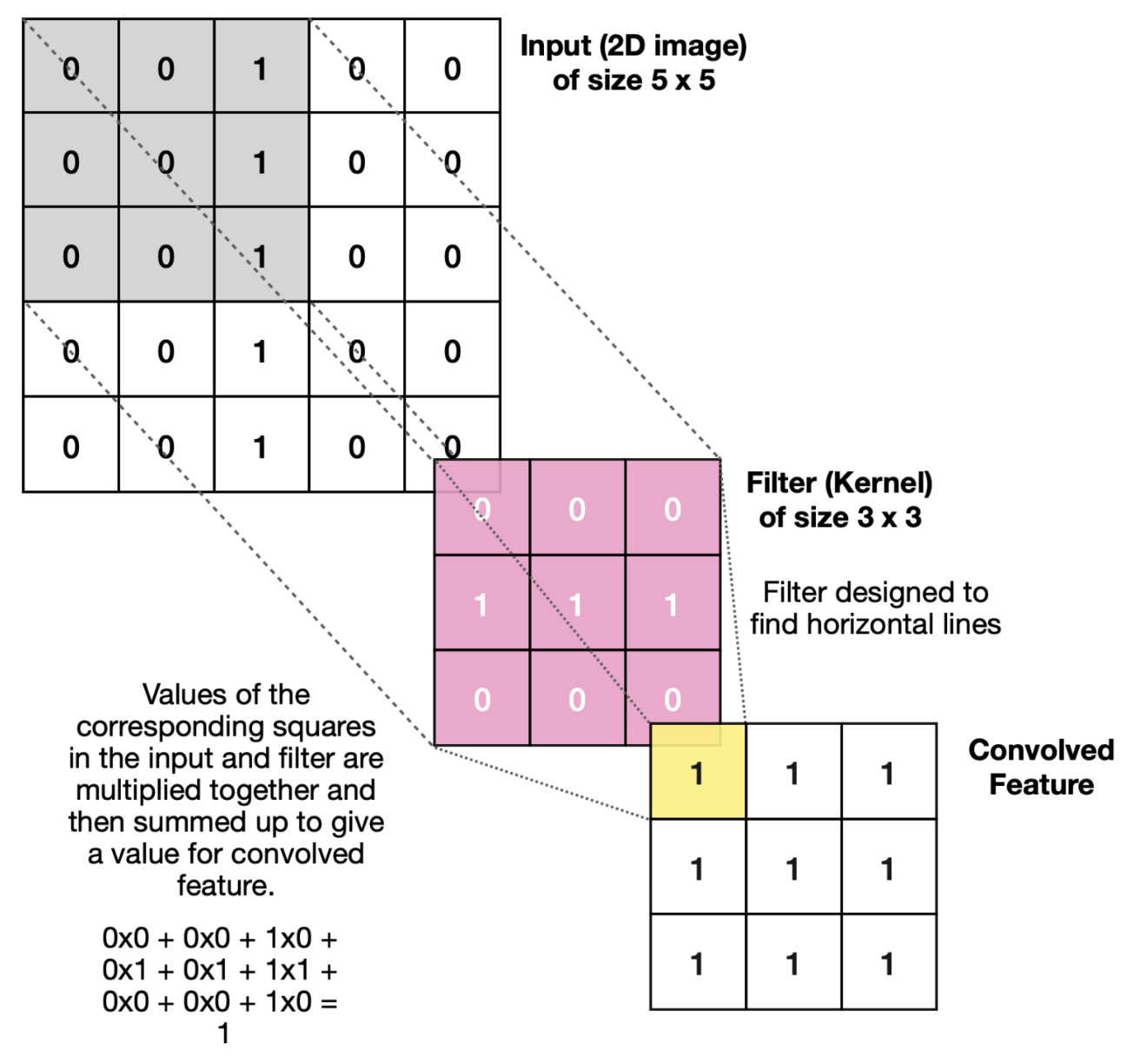
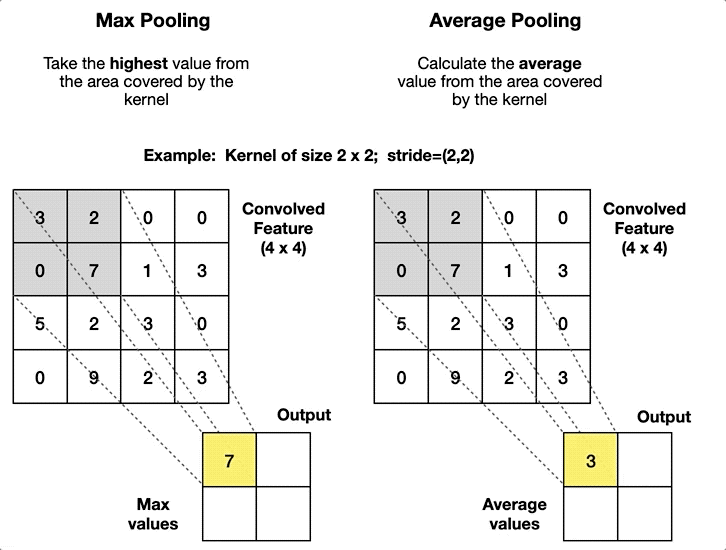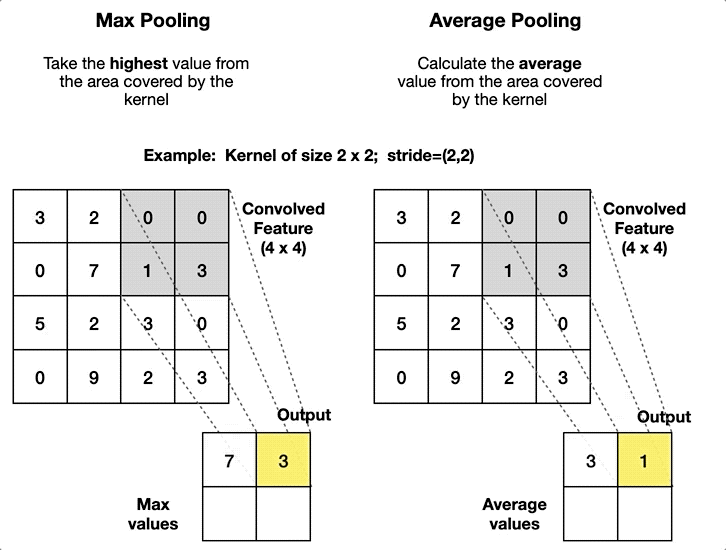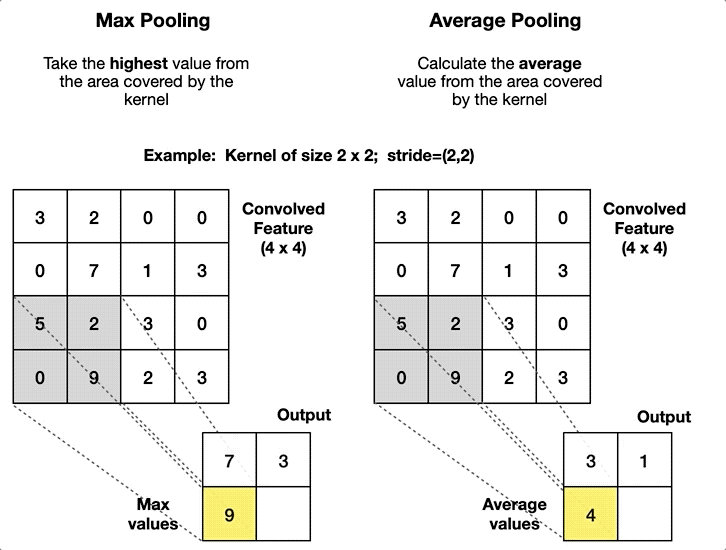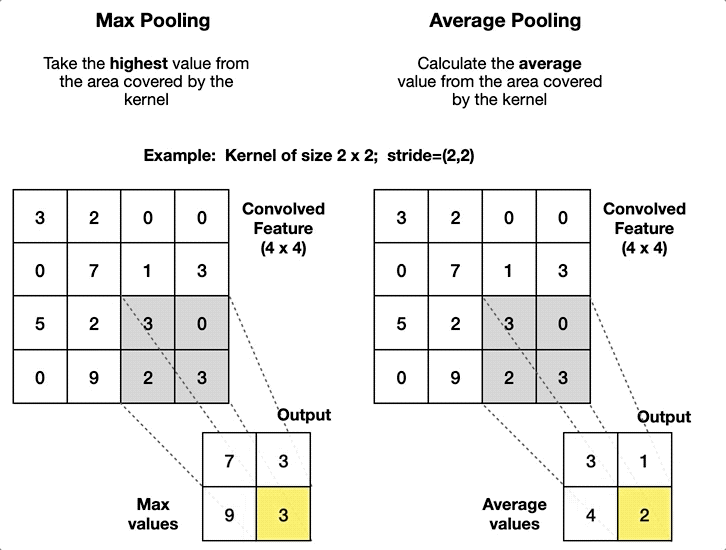
Weight sharing in CNNs
- What does this mean for learning?
\(\Rightarrow\) We have to learn the same thing in different locations!
\(\Rightarrow\) An “edge” remains an “edge”, no matter where we are. - Instead of training a fully connected layer, we train the weights of a kernel that moves over the input
- Same weights in every location \(\Rightarrow\) weight sharing!
- Architecture is closely related to fully connected NNs:
- Inner product between kernel weights \(\theta\) and input \(x\) \(\Rightarrow\) activation \(z\).
- Multiple kernels \(\Rightarrow\) multiple channels.
- Then comes a nonlinear activation function \(\sigma(z)\).
- Further followed by additional steps (see next slide).
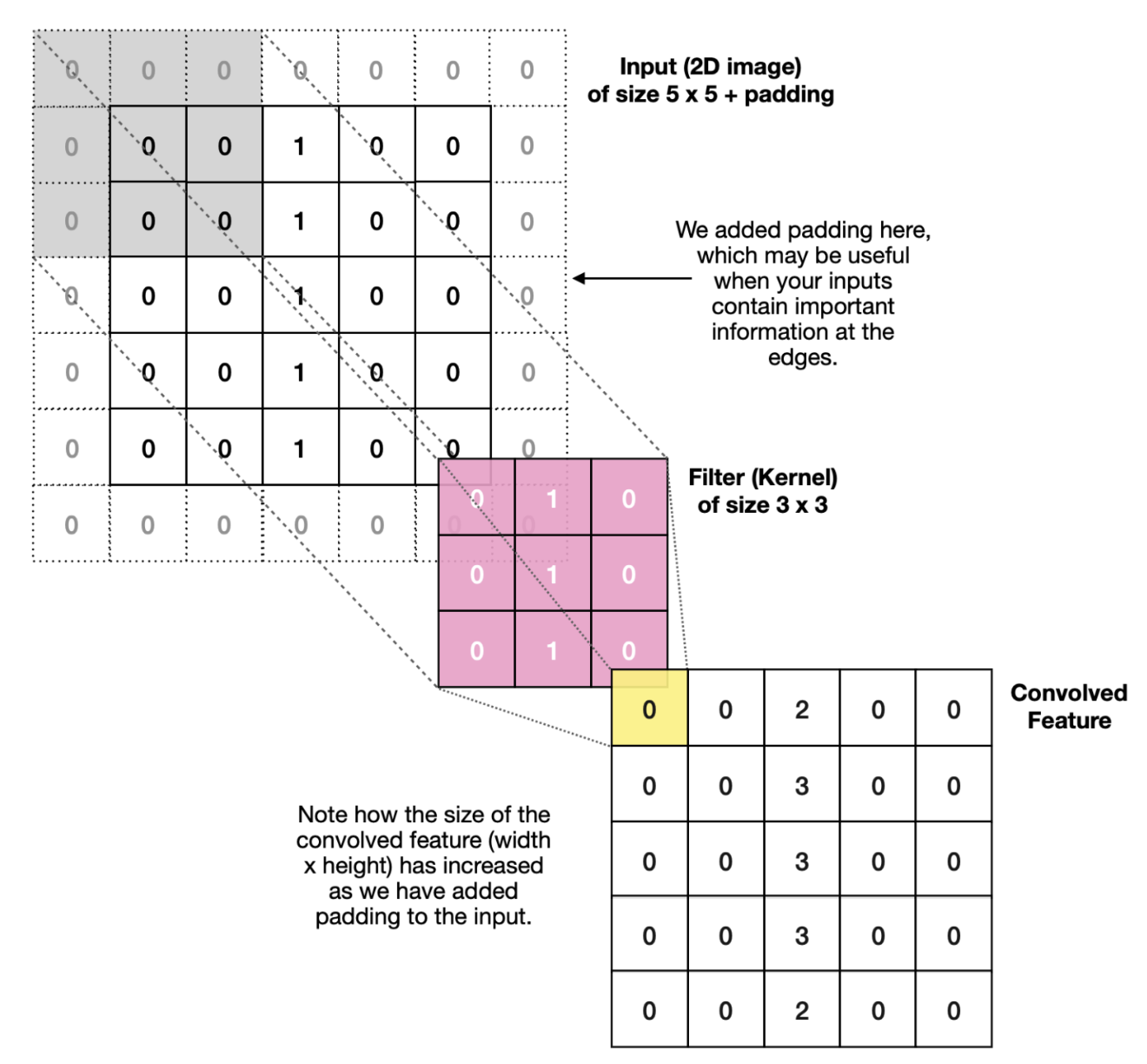
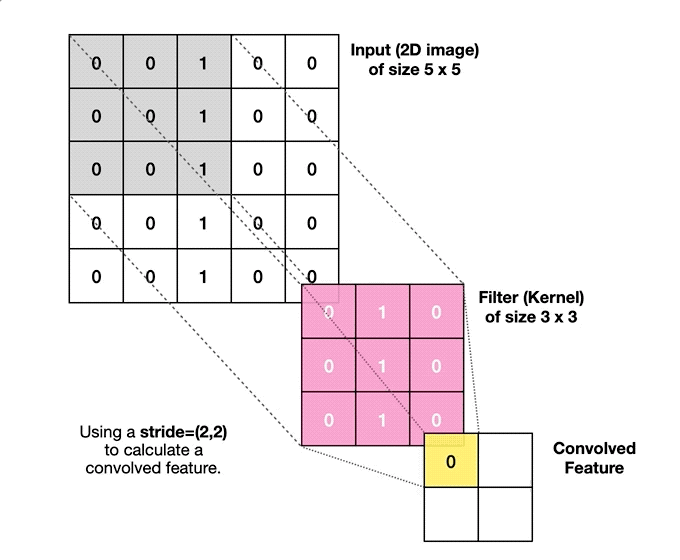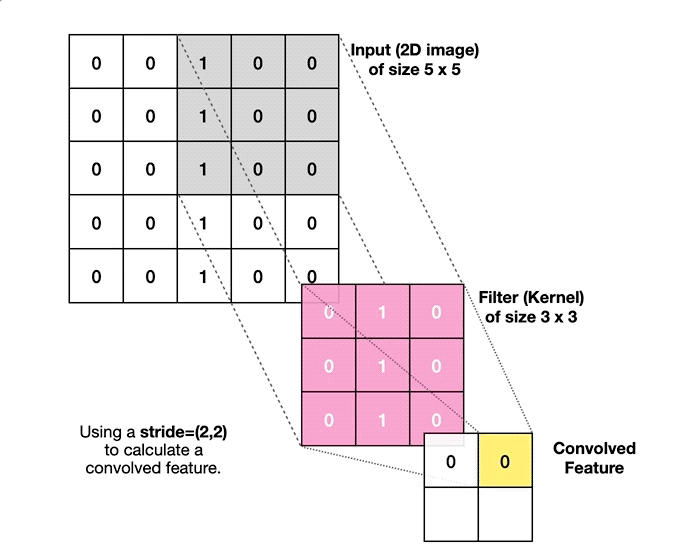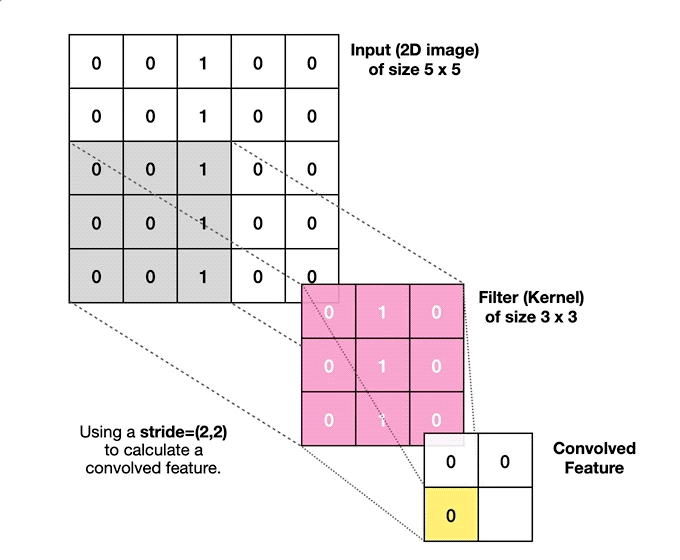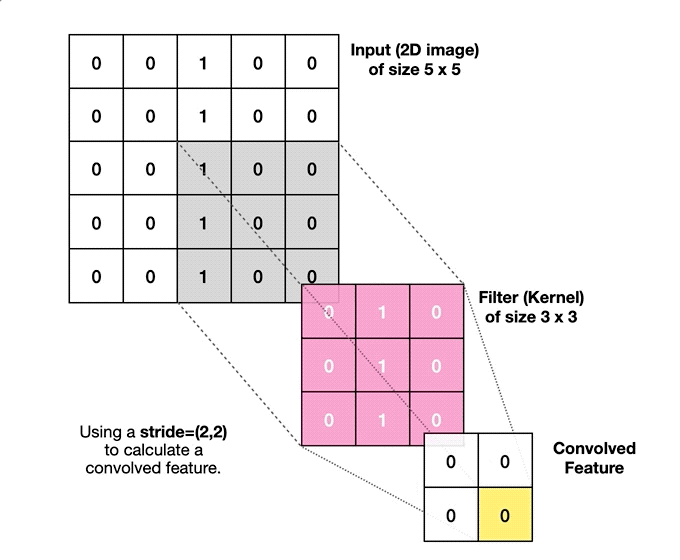
{kind=link}
Neural network architectures
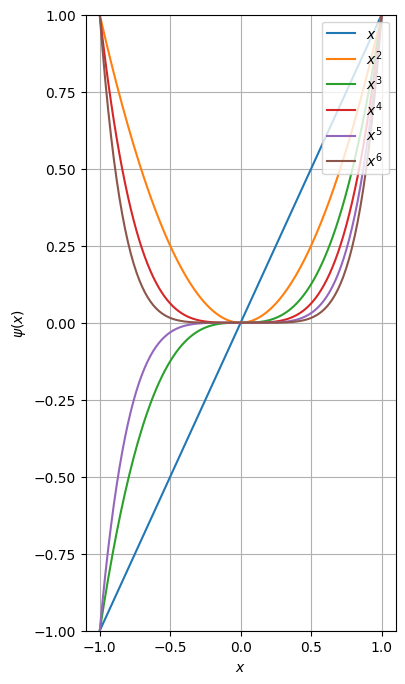
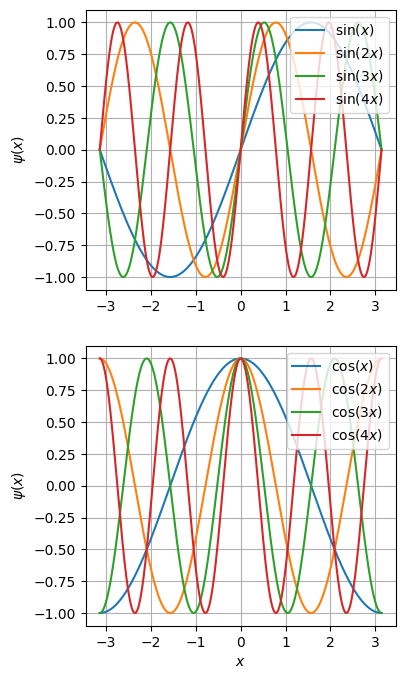
Features as an additional pre-processing step
- If we introduce feature functions \(\psi_i:\R^n \rightarrow \R\), \(\psi_i(x) = z_i\), then we can significantly improve the performance: \[ \psi(x) = [\psi_1(x), \ldots, \psi_q(x)]^\top. \]
- Different ways of introducing features: