Deep Reinforcement Learning
Deep Q Learning
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
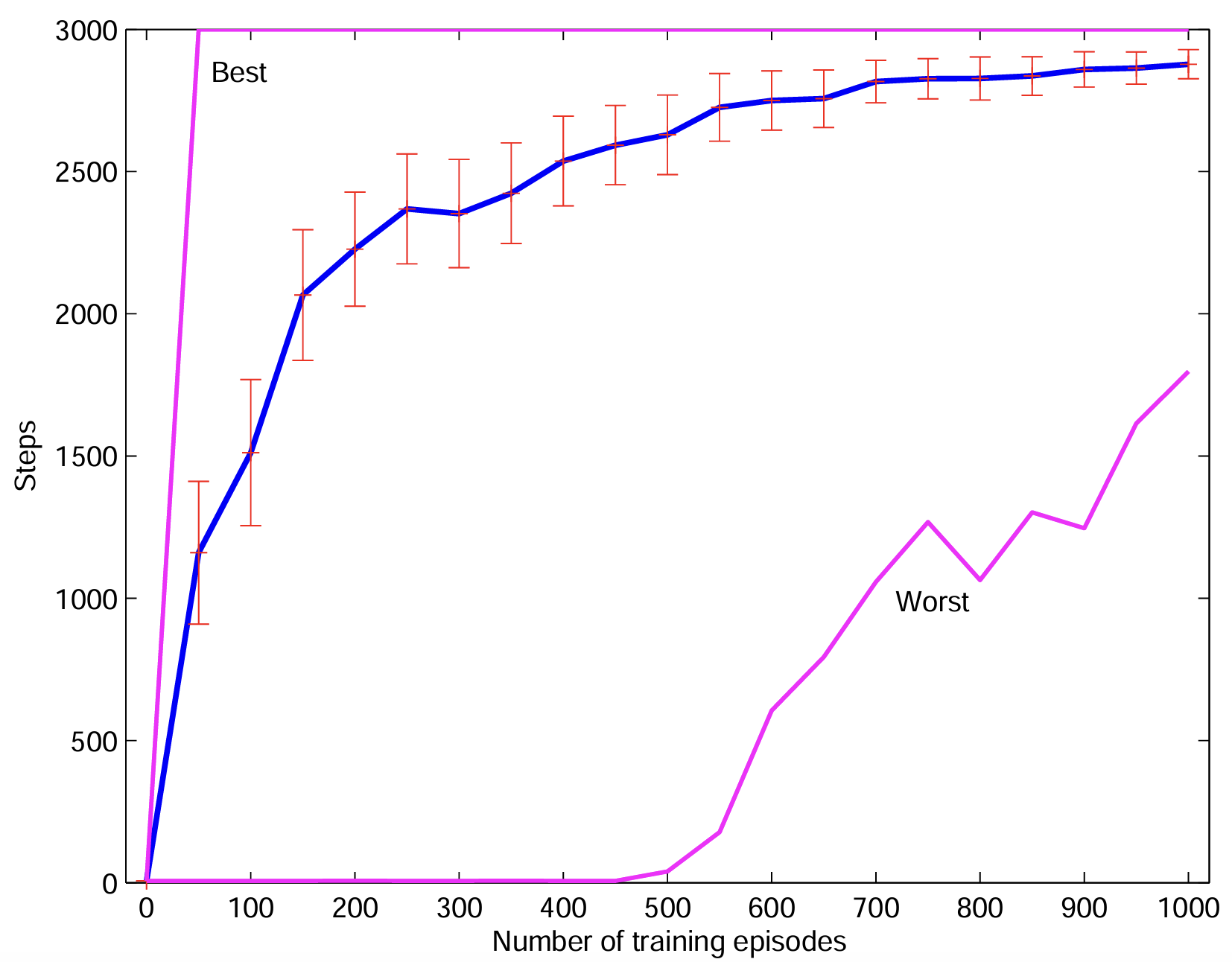
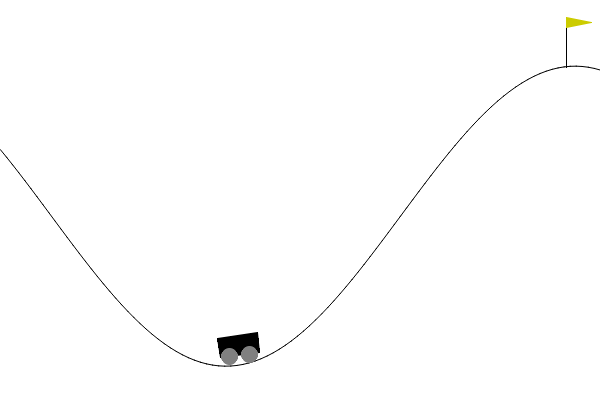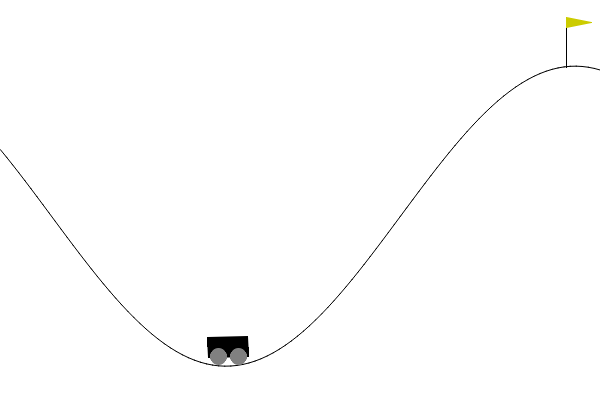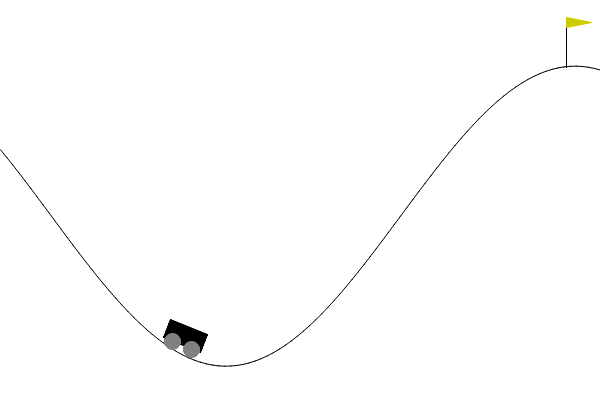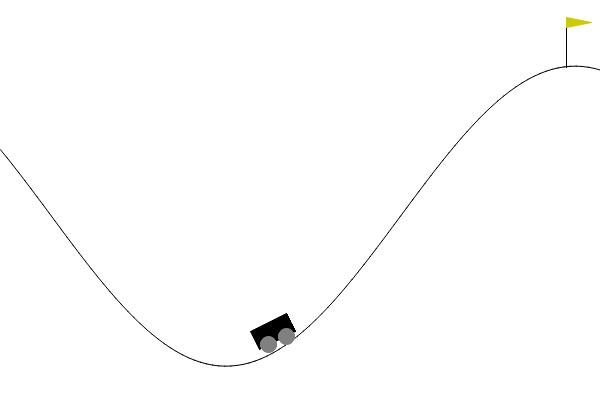
Example: Mountain car (1)
- Continous state \(s\in\Sc=[\submin{x},\submax{x}]\times[\submin{v},\submax{v}]\) (minimal and maximal position \(x\) and velocity \(v\)).
- Single, discrete action \(a\in\Ac=\set{-1,0,1}\).
- \(r = −1\) (goal is to terminate episode as quick as possible).
- Episode terminates when car reaches the flag (or max steps).
- Simplified longitudinal car physics with state constraints.
- Position initialized randomly within valley, zero initial velocity.
- Car is underpowered and requires swing-up.
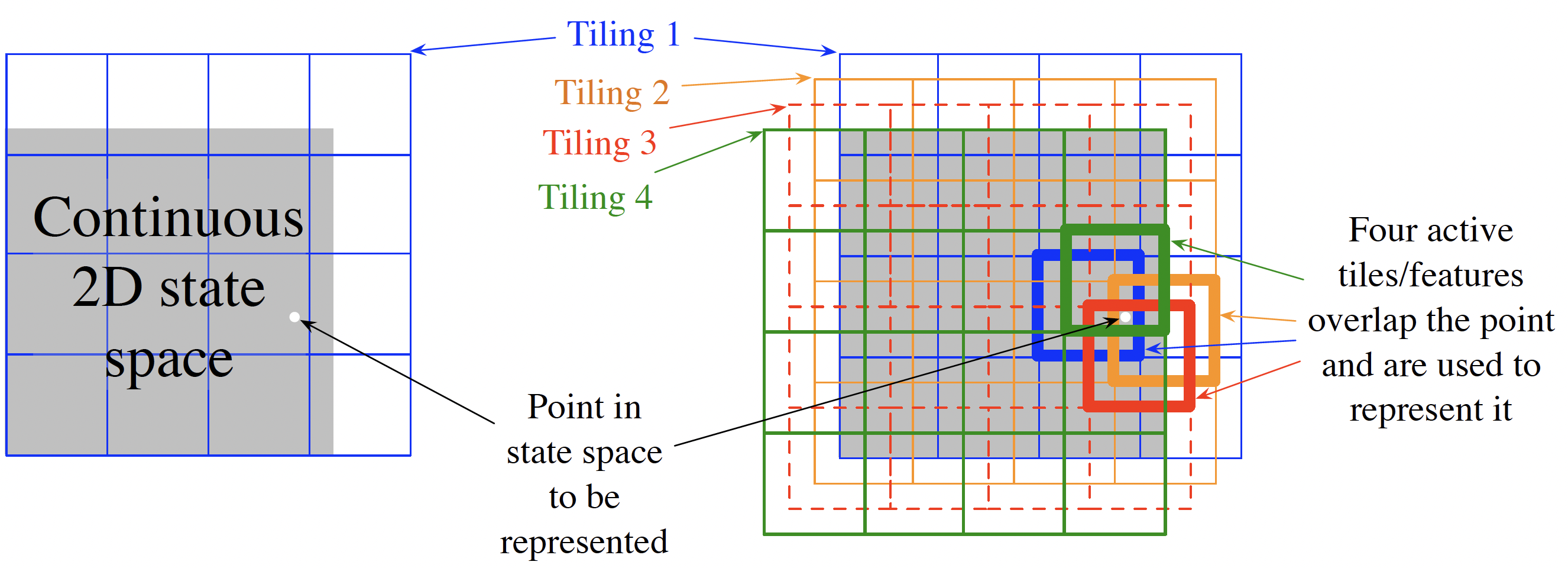
Approximation: Linear model with tile coding features \(x_i(s,a)\), where \[ \begin{align*} \psi(s,a)&=\sum_{i=1}^d \theta_i x_i(s,a), \\ x_i(s,a)&=\begin{cases} 1 & (s,a)\in\text{ tile \#}i \\ 0 & \text{otherwise} \end{cases}. \end{align*} \]
Example: Mountain car (2)
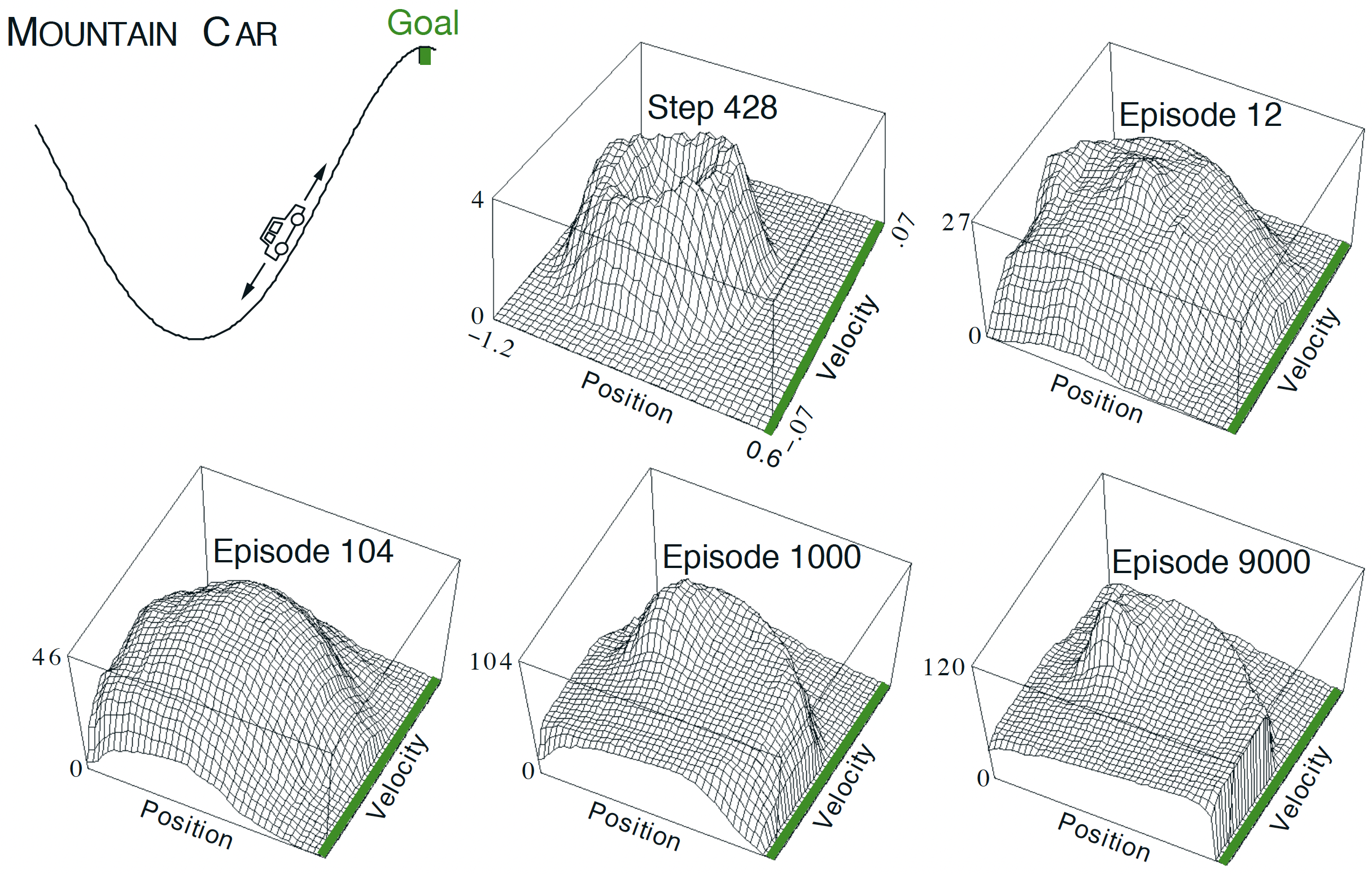
Warning: a huge drawback of function approximation
- Recall tabular policy improvement theorem: guarantee to find a globally better or equally good policy in each update step.
- Parameter updates of the form \(\eqref{eq:DQL_Q_update}\) have an impact on \(Q(s,a)\) for all \(s\) and \(a\), not just the one we visited!

Loss of the policy improvement theorem
- When using function approximation, the policy improvement theorem does no longer apply.
- While improving the policy, we may impair it in other places at the same time.
Example: Atari game Pong (1)
- State \(s\):
- \(210 \times 160\) pixels with \(3\) channels each (RGB) and values \(s_{i}\in\{0,\ldots,255\}\),
- stacking of multiple frames,
- some additional preprocessing.
- Action \(a\): \(18\) actions in total, (\(6\) buttons, some of which can be pushed at the same time).
- Architecture for \(Q_\theta\) (Mnih et al. 2015):
 \(\qquad\)
\(\qquad\) 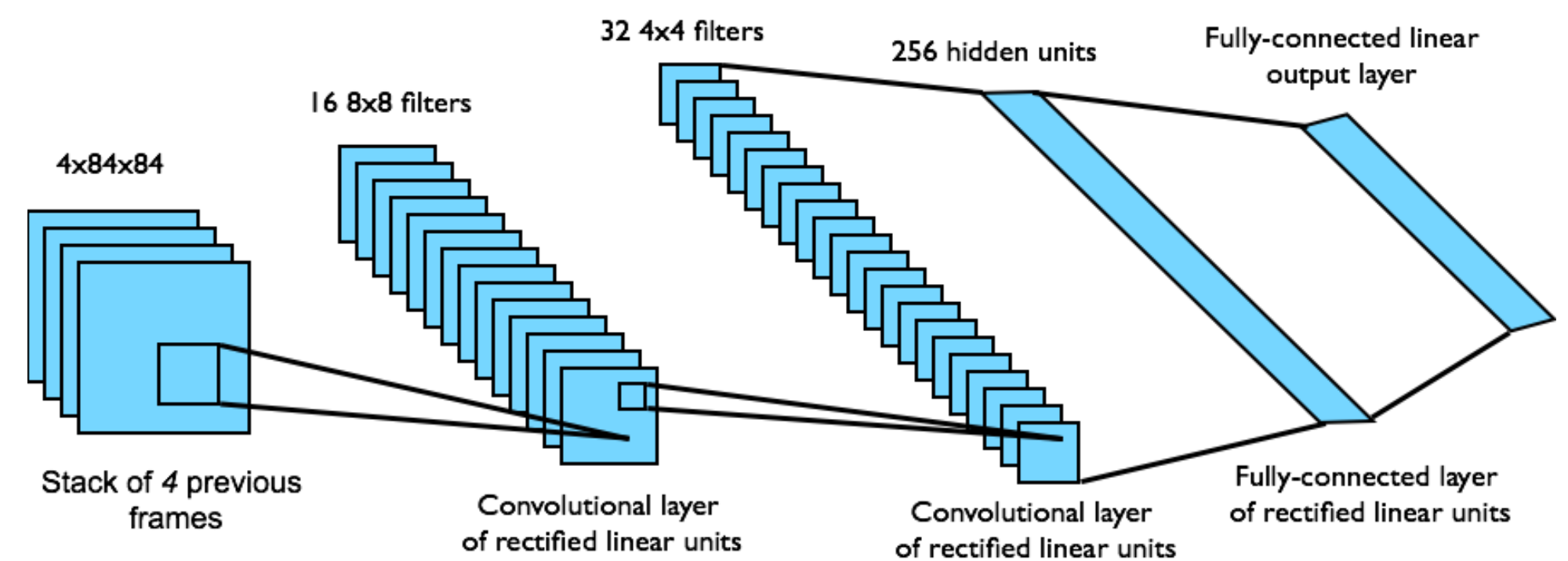
- Loss function \(L(\theta)\): Huber loss \(L_\beta(\theta) = \begin{cases} \frac{1}{2}\theta^2, & \theta \leq \beta \\ \beta(\abs{\theta} - \frac{1}{2}\theta), & \text{otherwise} \end{cases}\).
- Training: RMSProp descent algorithm.
- Annealing of the exploration rate: \(\epsilon\) goes from \(1\) to \(0.1\) (or \(0.05\)) over the first \(10^6\) frames.


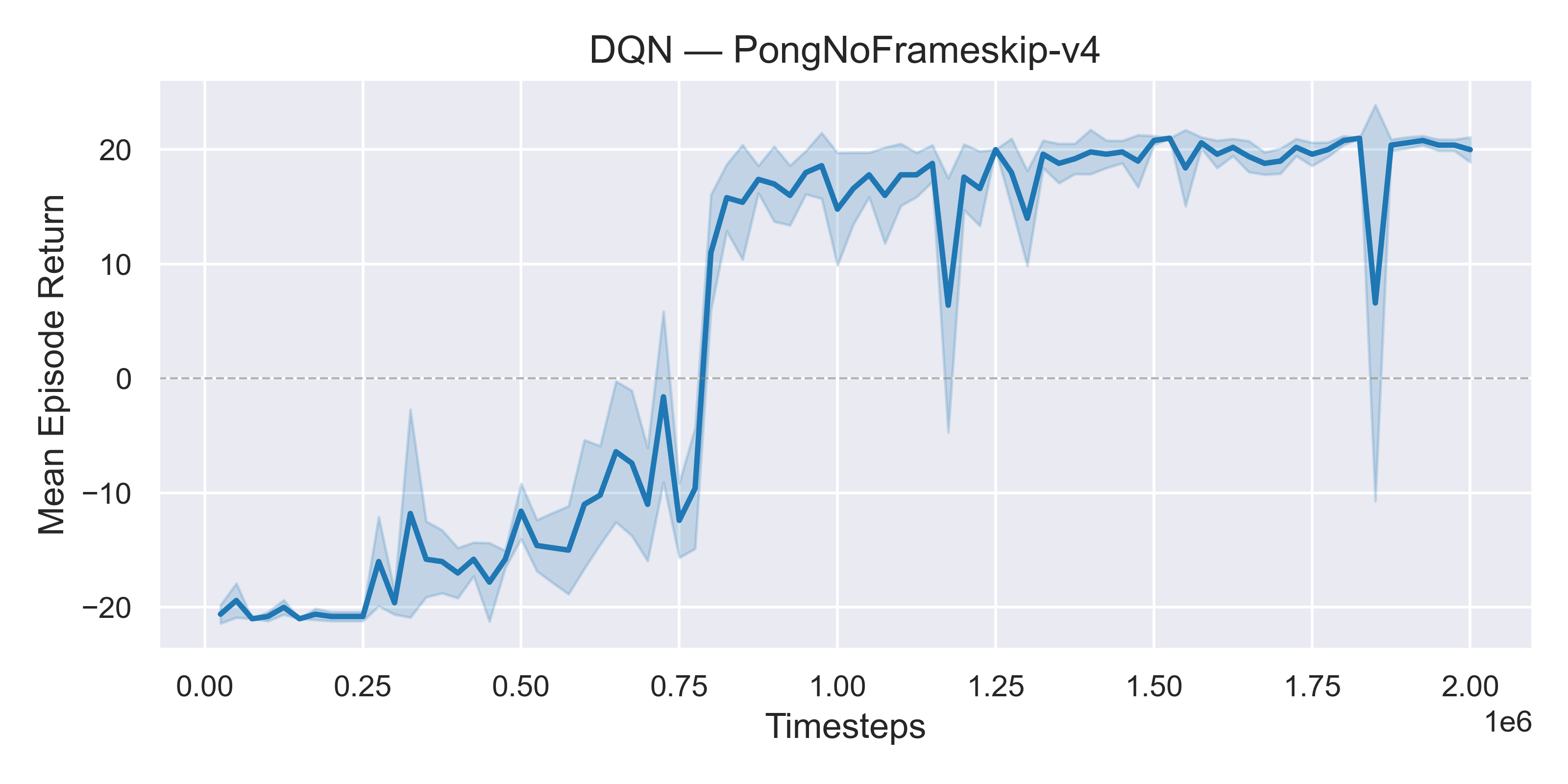
Example: Atari game Pong (2)

 100,000 steps
100,000 steps
 300,000 steps
300,000 steps
 500,000 steps
500,000 steps
 800,000 steps
800,000 steps
 1,000,000 steps
1,000,000 steps
 1,500,000 steps
1,500,000 steps
 2,000,000 steps
2,000,000 steps
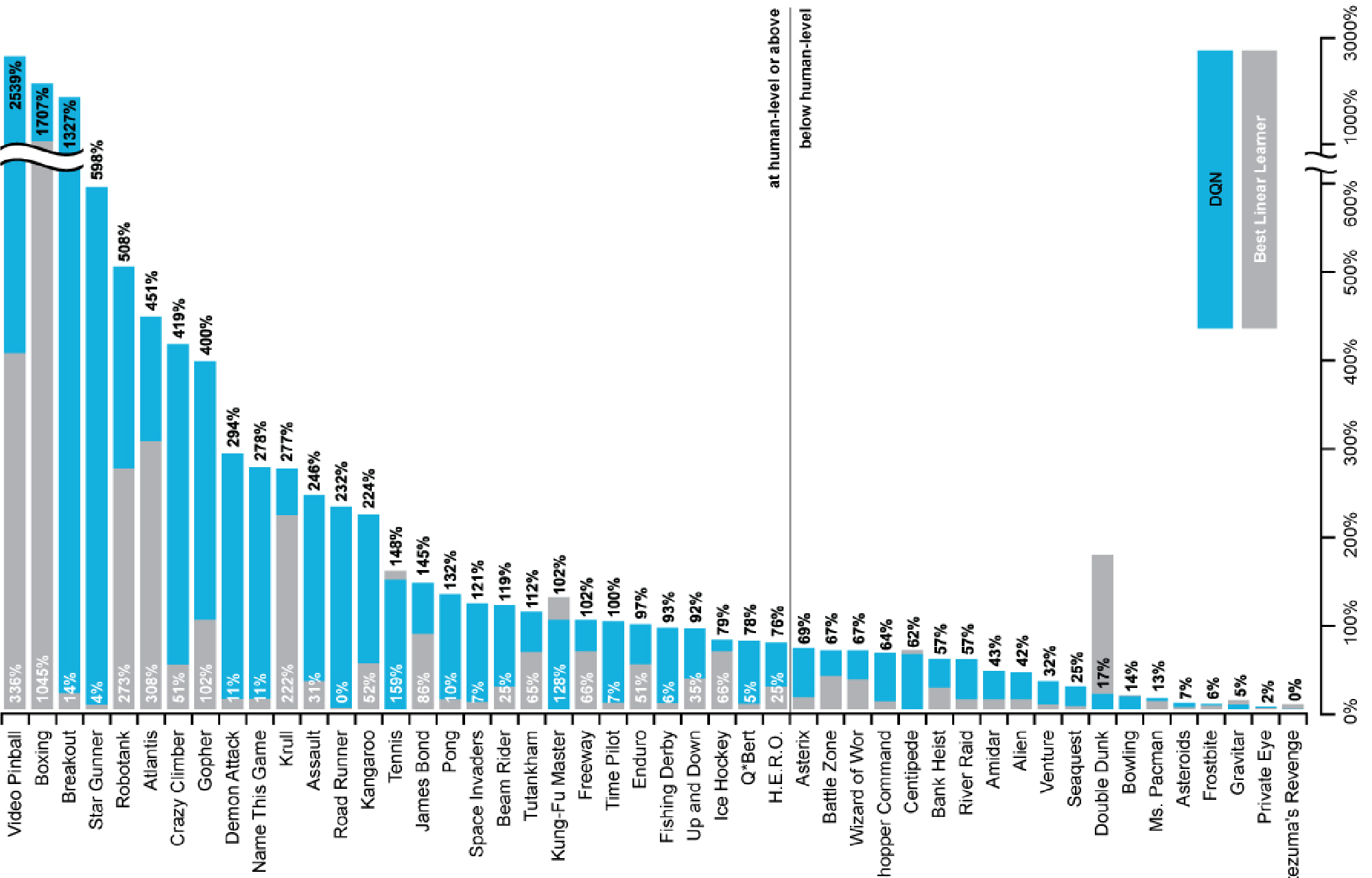
Example: Atari games
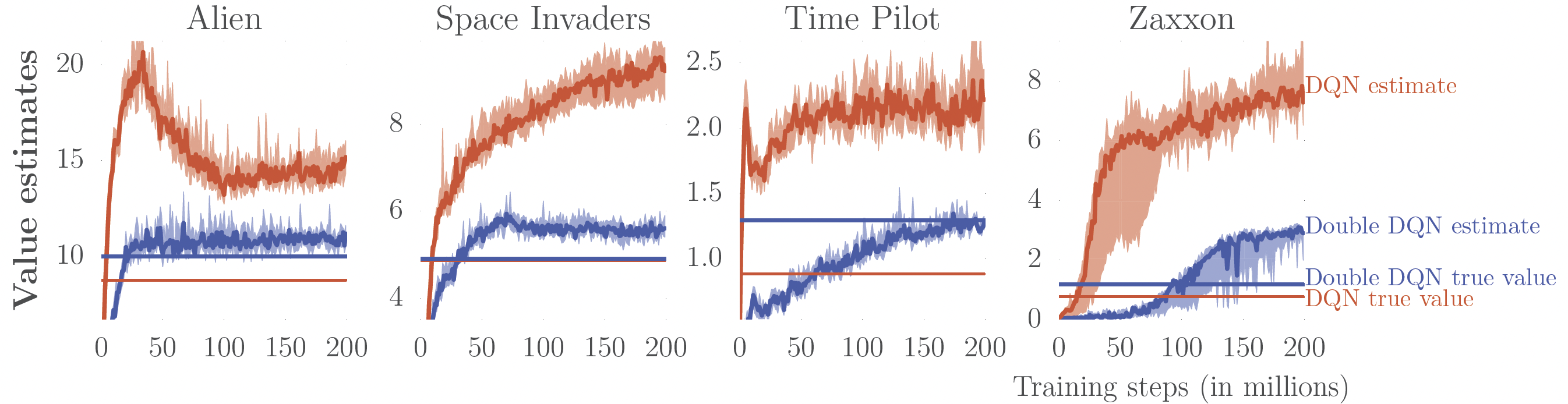
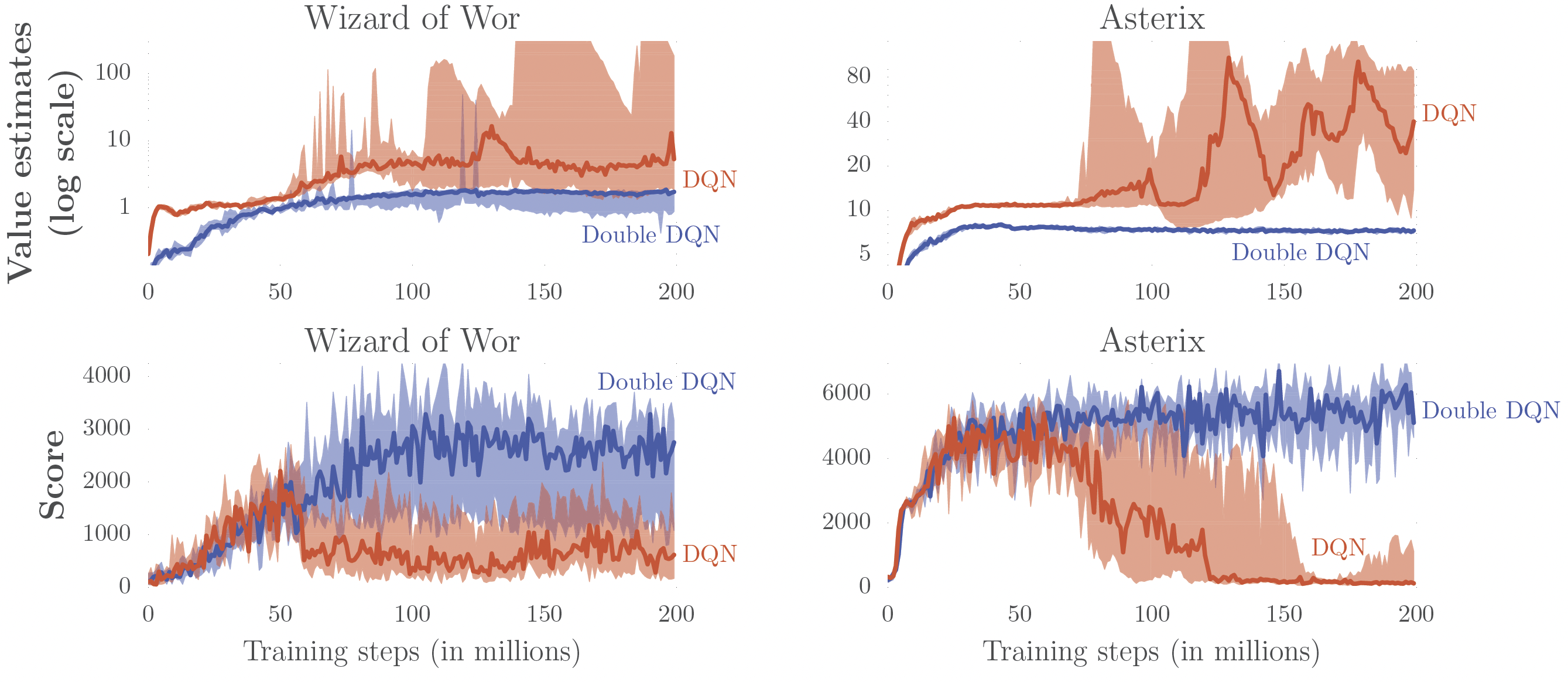
Double \(Q\) networks (Hasselt, Guez, and Silver 2016)
Remember the maximization bias and double \(Q\)-learning?
\(\Rightarrow\) Don’t use same network to choose the action and estimate the value!
Double deep \(Q\)-learning:
- Just use the current network (\(\theta\)) to evaluate the action.
- Still use the target network (\(\bar{\theta}\)) to evaluate the value. \[y = r + \gamma \textcolor{red}{Q_{\bar{\theta}}}(s',\arg\max_{a\in\Ac} \textcolor{blue}{Q_\theta}(s',a))\]
Algorithm recap: Tabular Q-Learning.
- Take \(a_t\) (\(\epsilon\)-greedy on \(Q_1 + Q_2\)), observe \((r_t,s_{t+1})\)
- if \(\mathsf{rand()} > 0.5\) then \[\begin{align*} &y = r_t + \gamma \textcolor{red}{Q_2}(s_{t+1},\arg\max_{a\in\Ac} \textcolor{red}{Q_1}(s_{t+1},a))\\ &Q_1(s_t,a_t) \gets Q_1(s_t,a_t) + \alpha \left[y - Q_1(s_t,a_t)\right] \end{align*}\]
- else: …
Prioritized experience replay (Schaul et al. 2016)
- Samples in the replay buffer are not equally important.
- From some examples, you can learn more than from others.
- What would be a good criterion to assess the relevance of a particular sample? \(\Rightarrow\) The TD error \[\delta_i = r_i + \max_{a\in\Ac}Q_{\bar{\theta}}(s_i',a) - Q_\theta(s_i,a_i)\]

- Instead of sampling uniformly from the replay buffer, we assign an individual probability to each sample: \[ P(i) = \frac{p_i^\alpha}{\sum_{k=1}^{\abs{\Dc}}p_k^\alpha}, \qquad p_i = \abs{\delta_i} + \epsilon.\]
- Here, \(\alpha\geq 0\) determines the degree of prioritization (\(\alpha=0\) is the uniform case).
- The parameter \(\epsilon>0\) ensures that all samples are drawn with non-zero probability.
- A version that’s less sensitive to outliers: rank the transitions according to \(\abs{\delta_i}\): \[p_i = \frac{1}{\mathsf{rank}(i)}.\]
- But: this introduces a bias (we sample from a different, uncontrollable distribution) \(\Rightarrow\) Use importance sampling!
Some practical tips
Following Sergey Levine’s CS285 lecture:
- Q learning takes some care to stabilize.
- Test on easy, reliable tasks first, make sure your implementation is correct.
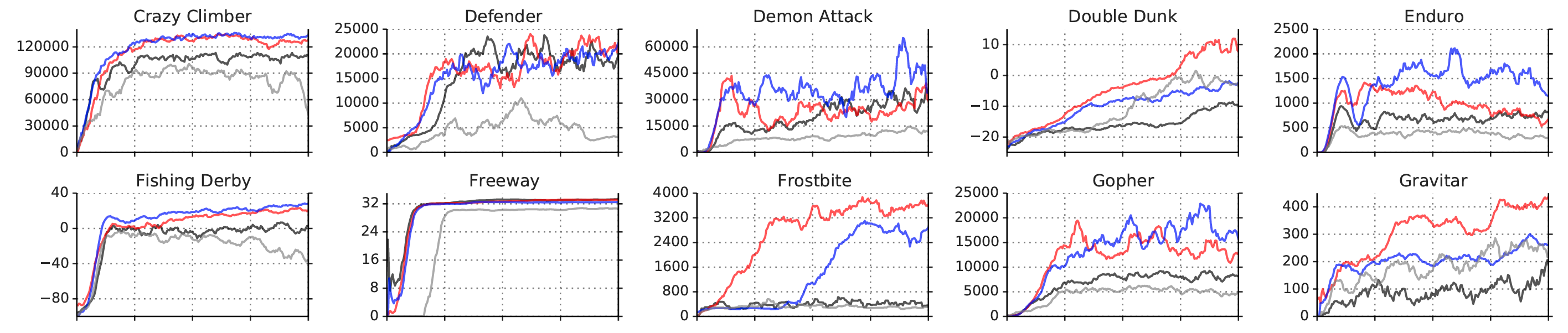 (Schaul et al. 2016)
(Schaul et al. 2016)
- Test on easy, reliable tasks first, make sure your implementation is correct.
- Large replay buffers help improve stability.
- Looks more like fitted Q iteration.
- It takes time, be patient; performance might be no better than random for a while.
- Start with high exploration (\(\epsilon\)) and gradually reduce.
- Bellman error gradients can be big; clip gradients or use Huber loss.
- Double Q learning helps a lot in practice: it’s simple and has no downsides.
- \(n\)-step returns also help a lot, but have some downsides.
- Schedule exploration (high to low) and learning rates (high to low). The Adam optimizer can help too.
- Run multiple random seeds, it’s very inconsistent between runs.
Least squares policy iteration (LSPI)
General idea:
- Apply general policy improvement (GPI) based on dataset \(\Dc\),
- Policy evaluation by off-policy LS-SARSA,
- Policy improvement by greedy choices on predicted action values.
Some remarks:
- LSPI is an offline and off-policy control approach.
- Exploration is required by feeding suitable sampling distributions to \(\Dc\):
- \(\epsilon\)-greedy choices based on \(Q_\theta\).
- Completely random samples are conceivable as well.
Example: Pendulum on a cart (Abdelwanis et al. 2026)