Deep Reinforcement Learning
Advanced Algorithms (Part II)
Chair of Safe Autonomous Systems, TU Dortmund
Summer term 2026
The problem of continuous actions in \(Q\)-learning
- In a standard DQN, the optimal policy is implicit.
- To choose the best action \(a\) in a given state \(s\), the agent evaluates the \(Q\)-values for all possible actions and picks the one that maximizes the expected return: \[\pi(s) = \arg\max_{a} Q^*(s, a)\]
- Works well for discrete action spaces (e.g., Left, Right, Jump).

- For continuous \(\Ac\) (e.g., controlling the torque of a robotic joint), we have an infinite number of possible actions.
- To find the absolute maximum of the \(Q\)-function in this scenario, we can pursue two options (both very expensive):
- Discretize the action space. For instance, if we have \(7\) joints and discretize each into just \(10\) levels, we get \(10^7\) possible actions.
\(\Rightarrow\) The “curse of dimensionality” makes this computationally impossible to solve in real-time. - Optimization. An iterative optimization algorithm (e.g., gradient ascent) inside the environment loop to find the maximizing \(a\) before each step.
- Discretize the action space. For instance, if we have \(7\) joints and discretize each into just \(10\) levels, we get \(10^7\) possible actions.
Approach: Merging DQN and Actor-Critic
Instead of maximizing over \(Q\), we introduce a function \(a = \mu_\phi(s)\) such that \(Q^*(s, \mu_\phi(s)) \approx \max_{a} Q^*(s, a)\).
Challenges:
- We now have to optimize for the policy directly \(\Rightarrow\) policy gradient!
- In off-policy algorithms like \(Q\)-learning, the variance becomes an even bigger problem!
- Off-policy policy gradient.
- Deterministic policies with reduced variance.
The four main changes over DPG
- Integration of deep neural networks (CNNs)
- Introduction of the replay buffer
- Larger datasets to train from.
- Allows for i.i.d. sampling / breaks the temporal correlation of data.
- Explicit action noise for exploration
- Deterministic actor in DPG: it cannot explore on its own.
- DDPG adds an explicit random process \(\Nc\) directly to the action selection during environment interaction.
- The original paper utilized Ornstein-Uhlenbeck noise, which creates temporally correlated, mean-reverting patterns that mimic inertial drift.
- Transition to “soft updates” for target networks
- In DQN, target network weights are periodically copied exactly from the online network every few thousand steps.
- For continuous actor-critic configurations, hard updates changed the value landscape too abruptly.
- Instead: soft update, where target networks track the online networks smoothly at every single training step using an interpolation factor \(\tau \ll 1\) (e.g., \(\tau = 0.001\)): \[\bar{\theta} \leftarrow \tau \theta + (1 - \tau)\bar{\theta}, \qquad \bar{\phi} \leftarrow \tau \phi + (1 - \tau)\bar{\phi}.\] \(\Rightarrow\) targets change slowly, providing an unmoving baseline that stabilizes the deep network’s gradients.
- We have seen this before under Polyak averaging.

The TD3 algorithm
- Interact: Sample \(\set{s_t,a_t,r_t,s_{t+1}}\) using \(a_t=\mu_\phi(s_t) + \epsilon\) (\(\epsilon\sim\Normal{0}{\sigma^2}\)) and store in the replay buffer \(\Dc\).
- Sample: Draw random mini-batch of \(N\) transitions: \(\Bc\subset\Dc\).
- Update critic: Calculate targets \(y_i\) by minimizing over two target networks (💡 the Twin): \[y_i = r_i + \gamma \min_{j\in\set{1,2}} Q_{\bar{\theta}_j}(s_{i+1}, \tilde{a}_{i+1}), \qquad\text{with \textcolor{red}{noisy action} }\tilde{a}_{i+1}=\mu_{\bar{\phi}}(s_{i+1}) + \epsilon, \quad\epsilon \sim \mathsf{clip}(\mathcal{N}(0, \tilde{\sigma}^2), -c, c).\] The two critics are updated by minimizing the Bellman errors: \[L_Q(\theta_j) = \frac{1}{N}\sum_{i} \cbracket{y_i - Q_{\theta_j}(s_i, a_i)}^2, \qquad \theta_j \gets \theta_j + \alpha_\theta \frac{2}{N} \sum_{i=1}^N \cbracket{y_i - Q_{\theta_j}(s_i, a_i)} \nablatheta Q_{\theta_j}(s_i,a_i).\]
Perform next steps only every \(n_\mathsf{up}\) steps: (💡 the Delayed):
- Update actor: \[\phi \gets \phi + \alpha \frac{1}{N} \sum_{i=1}^N \nablaa Q_{\textcolor{red}{\theta_1}}(s_i,a)\Big|_{a=\mu_\phi(s_i)} \nablaphi \mu_\phi(s_i).\]
- Soft updates: Incremental target updates (\(\bar{\phi}\) / \(\textcolor{red}{\bar{\theta}_1}\) / \(\textcolor{red}{\bar{\theta}_2}\)).

Example: Half-Cheetah
Half Cheetah from the MuJoCo library.
- \(\Sc\): 17 states, \(\Ac\): 6 actions.
- Reward: Forward-Cost - Control-Cost.
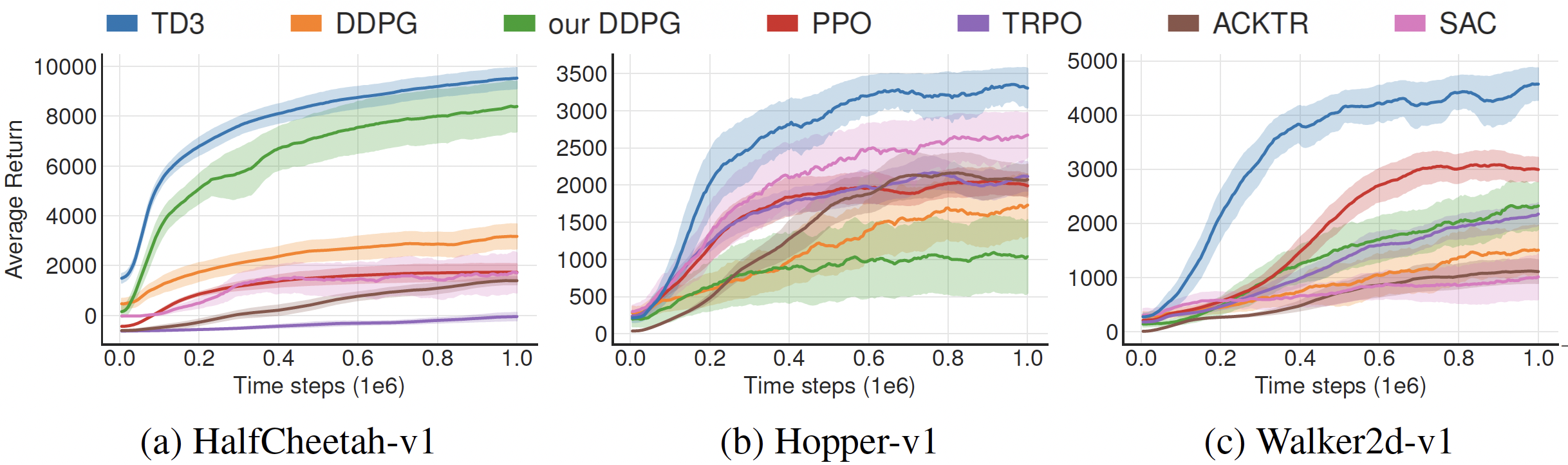
Results: TRPO vs. PPO vs. TD3 (from the RL Baselines3 Zoo)
The SAC algorithm

Example: Half-Cheetah
Half Cheetah from the MuJoCo library.
- \(\Sc\): 17 states, \(\Ac\): 6 actions.
- Reward: Forward-Cost - Control-Cost.
Results: TRPO vs. PPO vs. TD3 vs. SAC (from the RL Baselines3 Zoo)
Example: Some MuJoCo environments
💡 Trained models from StableBaselines3.
Notes
- The SAC results reported in the TD3 paper (Fujimoto, Hoof, and Meger 2018) (see left) are worse than the TD3 results.
- Reason: there were two versions of SAC in quick succession.
- The now-standard that we have discussed (Haarnoja, Zhou, Hartikainen, et al. 2018). It also considered some ideas from the TD3 paper such as twin \(Q\) networks to avoid maximization bias.
- The original one (Haarnoja, Zhou, Abbeel, et al. 2018) went out of fashion quickly, but appeared around the same time as TD3. It is thus likely that (Fujimoto, Hoof, and Meger 2018) compared against this version.